摘要:MyBatis 是一款优秀的持久层框架,用于简化复杂的 JDBC 代码。支持自定义 SQL、存储过程以及高级映射。
目录
[TOC]
数据访问与 ORM 框架
参考:
JDBC、ORM、JPA
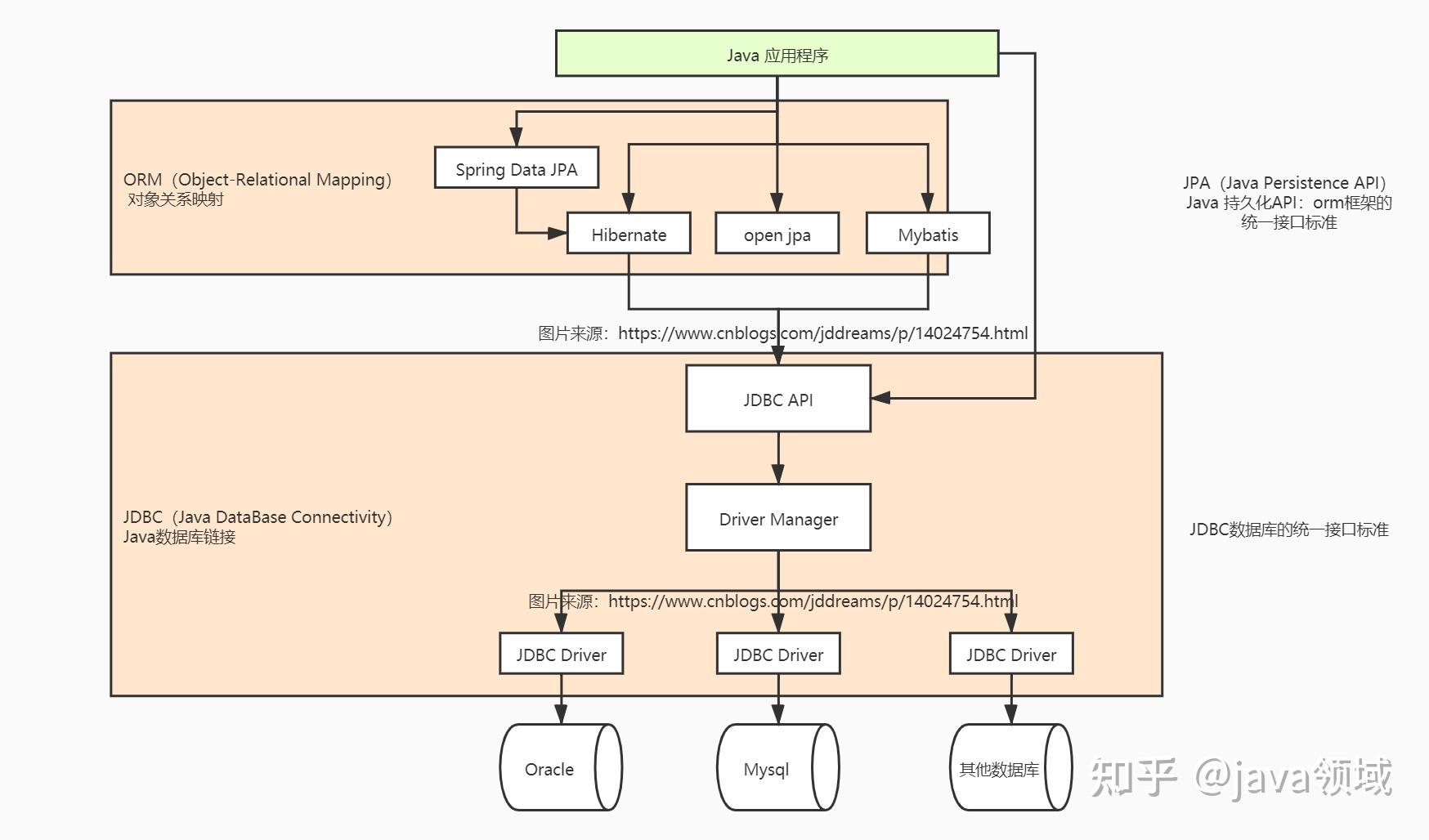
- JDBC(
Java DataBase Connectivity)API:是 Java 连接数据库操作的(底层的、原生的)统一接口标准。JDBC 对由各个数据库厂商及第三方中间件厂商依照JDBC规范(为数据库连接)提供的标准方法。Java程序员而言是API,为数据库访问提供统一接口标准。- 通过对应的
DriverManager(MySQL JDBC Driver、Oracle JDBC Driver等)去操作具体的数据库。 JdbcTemplate:是Spring的一部分,是Spring对JDBC的封装,目的是使JDBC更加易于使用。处理了资源的建立和释放。帮助我们避免一些常见的错误,比如忘了总要关闭、连接。
- ORM(
Object Relational Mapping)框架:对象–关系映射,用于建立 Java Object 实体类和数据库表之间的映射,从而达到操作实体类就相当于操作数据库表的目的。- ORM框架中贯穿着 JAVA 面向对象编程的思想;是对象持久化的核心。
- 常见的 ORM 框架有:
Hibernate、spring data jpa、open jpa。
- JPA(
Java Persistence API)API:Java 持久化 API,是 Java 应用程序访问 ORM 框架的统一接口标准/规范),实现用同样的方式访问不同的 ORM 框架。 - Spring Data JPA:是
Spring提供的一套简化JPA开发的框架。按照约定好的方法命名规则写DAO层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作,提供了CRUD、分页、排序、复杂查询等功能。- 可以理解为是对
JPA规范的再次封装抽象。不是一个完整JPA规范的实现,只是一个代码抽象层,主要用于减少为各种持久层存储实现数据访问层所需的代码量。其底层依旧是Hibernate框架。
- 可以理解为是对
关系:
- JDBC、ORM 框架、JPA 均属于持久化层,介于业务层和数据库之间。
- jdbc 是数据库的统一接口标准;jpa是orm框架的统一接口标准。
- jdbc更注重数据库,orm则更注重于java代码,但是实际上jpa实现的框架底层还是用jdbc去和数据库打交道。
参考:
Hibernate 与 MyBatis
- Hibernate:是一个开源、全自动化的(标准的)ORM 框架,将
POJO实体类与数据库表建立映射关系,可自动生成 SQL 语句并执行。对 JDBC 进行了非常轻量级的对象封装,封装了基本的 DAO 层操作,有较好的数据库移植性。- 面向对象,着力于对象(与对象)间的关系,用于解决计算机逻辑问题,考虑的是对象的整个生命周期(包括对象的创建、持久化、状态的改变和行为等),持久化只是对象的一种状态。
- MyBatis:是一个持久化、半自动化的
ORM框架,只支持将数据库查询结果映射到,而POJO实体类POJO到数据库的映射则需手动编写SQL语句实现。- 是一个持久化框架,不是依照的
JPA规范。 - 面向关系模型,着力于
POJO与SQL间的映射关系,用于解决数据的高效存取问题。 - 可用简单的 XML 或注解来配置和映射原生信息,将接口和
POJO映射成数据库中的记录。主要依赖于SQL的编写与ResultMap查询结果集的映射,需额外维护。 支持定制化SQL优化、存储过程及高级映射。避免了几乎所有的JDBC代码和手动设置参数及获取结果集。
- 是一个持久化框架,不是依照的
区别:查询关联对象(或关联集合对象)时,
Hibernate可根据 ORM 对象关系模型直接获取,所以是全自动的。- 而
MyBatis需手动编写 SQL 来完成,所以称为半自动的。
选型:
- 进行底层编程,对性能要求高,直接用
JDBC; - 直接操作数据库表,没有过多的定制,用
Hibernate; - 灵活使用 SQL 语句,用
MyBatis;
JDBC 访问数据库
JDBC操作的几个关键环节:
- 引入依赖,配置数据库连接;
- 根据使用的DB类型不同,加载对应的 JdbcDriver 驱动;
- 连接 DB;
- 编写SQL语句;
- 发送到DB中执行,并接收结果返回;
- 对结果进行处理解析;
- 释放过程中的连接资源。
如:
1 | |
application.yml 中:
1 | |
JPA
各层常用注解
控制层:
@Controller@Autowired:属性上
业务层:
@Service:Pageable 接口、PageHelper 分页插件
Repository 数据接口层:Spring Boot 中 Repository 的使用
@Repository: 见声明/注册 Bean 的注解;@CrudRepository:继承了Repository接口,并新支持对实体类的增删改查等方法;@PagingAndSortingRepository:继承了CrudRepository接口,并新支持分页、排序及根据条件查询等方法;@JpaRepository对应接口:包括 JPA 提供的增删改、分页查询及排序查询等。
1 | |
Entity 层注解
Entity 数据持久层:
@Entity:标注在类上,表示数据库持久化类,对应一个数据库实体。[name]可选属性,默认为所标注的实体类名。因为用类反射机制Class.newInstance()方法创建实例的需要,至少有一个无参构造方法。也可标注抽象类。
@NamedQuery:标注在接口的自定义查询方法上,指定要执行的查询语句;@NamedQueries:定义多个;serialVersionUID:适用于JAVA序列化机制。简单来说,通过判断类的serialVersionUID来验证版本一致。- 在进行反序列化时,JVM会把传来的字节流中的
serialVersionUID与本地相应实体类的serialVersionUID进行比较。 - 如果相同说明是一致的,可以进行反序列化,否则会出现反序列化版本一致的异常,即是
InvalidCastException。
- 在进行反序列化时,JVM会把传来的字节流中的
1 | |
@Query:标注在(继承JpaRepository接口的)自定义查询方法上,指定要执行的查询语句;@Modifying:支持更新类的 Query 语句,配合@TransactionalSpring 事务 使用;
1 | |
@Table:标注在类名前,设置数据库表名;name属性:表示实体对应表名,默认为实体名;catalog和schema(思gay玛)属性:表示目录名或数据库名,根据不同的数据类型有所不同;uniqueConstraints属性:表示该实体所关联的唯一约束条件,可有多个唯一约束;默认没有,需配合@UniqueContraint用。
1 | |
@Temporal:时间;@Column:表示持久化属性映射表中的字段。标注在getter()或属性前。unique属性:字段为唯一标识,默认为 false。也可用@Table中的@UniqueConstraint,如上。nullable属性:字段可为 null,默认为 true(允许为 null)。insertable属性:在用 “INSERT” SQL 脚本插入数据时,需插入该字段的值。多用于只读属性,如主键和外键等。这些字段值通常是自动生成的。updatable,同上。columnDefinition属性:创建表时,字段对应创建的 SQL 语句,一般用于通过 Entity 生成表定义时。如@Column(columnDefinition = "tinyint(1) default 1"),设置字段类型和默认值。table属性:当映射多个表时,指定表中的字段。默认值为主表名。length属性:字段长度,当字段的类型为 varchar 时才有效,默认为255个字符。precision和scale属性:精度;当字段类型为 double 时,precision 表示数值的总长度,scale 表示小数点所占的位数。
1 | |
@Id:标注在属性上,表示该字段对应数据库中的列为主键。数据类型转换。能标识为主键的属性类型有:- 基本数据类型及其对应的封装类:
Character、Byte、Short、Integer、Long; - 大数值类型:
java.math.BigInteger; - 字符串类型:
java.lang.String; - 时间日期型:
java.util.Datejava.sql.Date
- 基本数据类型及其对应的封装类:
@GeneratedValue:指定主键生成策略。strategy属性:表示生成主键的策略,有:- GenerationType.TABLE:用一个特定的数据库表格来保存主键;
- GenerationType.SEQUENCE:用序列机制生成主键,不支持主键自增长,如 Oracle、PostgreSQL;
- GenerationType.IDENTITY:主键自增长,如 MySQL ;
- GenerationType.AUTO:默认,把主键生成策略交给持久化引擎,以上三种选一。
generator属性:为不同策略类型所对应的生成规则名。与@GenericGenerator搭配使用。
@TableGenerator@SequenceGenerator
1 | |
@Transient:声明不与数据库映射的字段,不需保存进数据库 。@Basicfetch属性:表示获取值的方式,默认为 EAGER(即时/非延迟加载),LAZY(惰性/延迟加载)。optional属性:表示是否可为 null,不能用于 Java 基本数据类型。
@Lob:声明为大字段。
1 | |
@Enumerated(EnumType.STRING):枚举类型的字段;@CreatedDate、@CreatedBy:表示为创建时间字段、创建人,在实体被 insert 时会设置值;@LastModifiedDate、@LastModifiedBy同理;
@EnableJpaAuditing:开启 JPA 审计功能。- 两个注解在程序运行的过程中不会起任何作用,只会在IDE、编译器、FindBugs检查、生成文档时有做提示。
@NonNull可以标注在方法、字段、参数之上,表示对应的值不可以为空@Nullable注解可以标注在方法、字段、参数之上,表示对应的值可以为空
SQL 数据类型转换
Java 数据类型与数据库中的类型转换由 JPA 实现框架自动转换,所以转换规则也不太一样。如 MySQL 中,varchar 和 char 类型都转化为 String 类型,Blob 和 Clob 类型可转化成 Byte[] 类型。
- 基本数据类型及其对应的封装类:
Character、Byte、Short、Integer、Long; - 大数值类型
java.math.BigIntegerjava.math.BigDecimal
- 字节和字符型数组:
byte[]、Byte[]、char[]、Character[] - 字符串类型:
java.lang.String - 日期时间类型
java.util.Datejava.util.Calendarjava.sql.Datejava.sql.Timejava.sql.Timestamp
- 用户自定义的枚举型
- Entity类型:标注为
@Entity的类 - 包含Entity类型的集合Collection类
java.util.Collectionjava.util.Setjava.util.Listjava.util.Map
- 嵌入式(embeddable)类
数据持久层演化
- MVC:
- 直接用 JDBC,model 实体层 (@Entity + @NamedQuery 写 SQL)
- JPA 数据接口层(extends JpaRepository + @Repository 注解)
- Spring MVC:
- Service 层 + ServiceImpl(剥离重复的业务逻辑,@Autowired 注入 Bean)
- DAO 数据持久层
- POJO:DO + VO + DTO,Lombok(实体类 Getter/Settor 注解)
- MyBatis 实现 Mapper 接口
- 全注解实现 Mapper(SQL 不够灵活)
- XML 实现 Mapper。工作量大。(MyBatis Generator 生成)
- MyBatis Plus 增强 + MapStruct(DO转VO) + Easy Trans 翻译
- 升华:不断封装,每个模块负责自己专业的领域,面向对象的思想
MyBatis
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。
- 用于简化复杂的 JDBC 代码。
- 避免了几乎所有的 JDBC 代码、手工设置参数、及获取结果集的工作,通过简单的 XML 或注解来配置、映射
原始类型、接口和Java POJO 对象为数据库中的记录。
参考:
- 优雅整合 SpringBoot+Mybatis
优雅整合 SpringBoot+Mybatis 多数据源- MyBatis 3 手册
- SpringBoot Guide
- MyBatis 《芋道 MyBatis 源码解析》 (opens new window)系列
优缺点
优点:
- 简单易学,容易上手(针对hibernate),一个是全自动ORM框架、一个是半自动ORM,基于SQL编程。
- 与
JDBC相比减少50%的代码量,消除冗余代码,不需要手动开关连接。 - 与各种数据库兼容:因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库 MyBatis 都支持。
- 提供第三方插件(分页插件、逆向工程)。
- 能够与 Spring 很好的结合。(配置文件、纯注解)
- 灵活:不会对应用程序或数据库的现有设计强加任何影响,SQL语句写在XML文件里,与程序彻底分离,解耦 SQL 语句与程序代码,便于统一化管理,并可重用;
- 提供 xml 映射标签,支持对象与数据库的 ORM 字段关系映射(
<resultmap>、@resultmap)。 - 支持动态 SQL;
缺点:
- SQL 语句依赖于数据库,数据库移植性差,不能随意更换数据库。。
- 虽然简化了数据绑定代码,但整个底层数据库查询实际还是要自己写,编写SQL语句工作量仍然很大,尤其是字段多、关联表多、多表查询时,不适合快速数据库修改。
- 解决:用
MyBatis-Generator插件自动生成通用 mapper。
- 解决:用
- 二级缓存机制不佳。
依赖和配置
引入依赖
1 | |
配置文件
Spring Boot 配置文件中指定扫描 mapper.xml 的位置。
Spring Boot 在配置文件(application.properties/yml)中配置 MyBatis,用来指定 mapper.xml 的位置(映射器接口的 xml 实现所在的项目路径)。
1 | |
配置类
MyBatis 配置类设置包路径。位置见 resources 配置文件;
@MapperScan:
1 | |
SqlSession 实例
工作原理
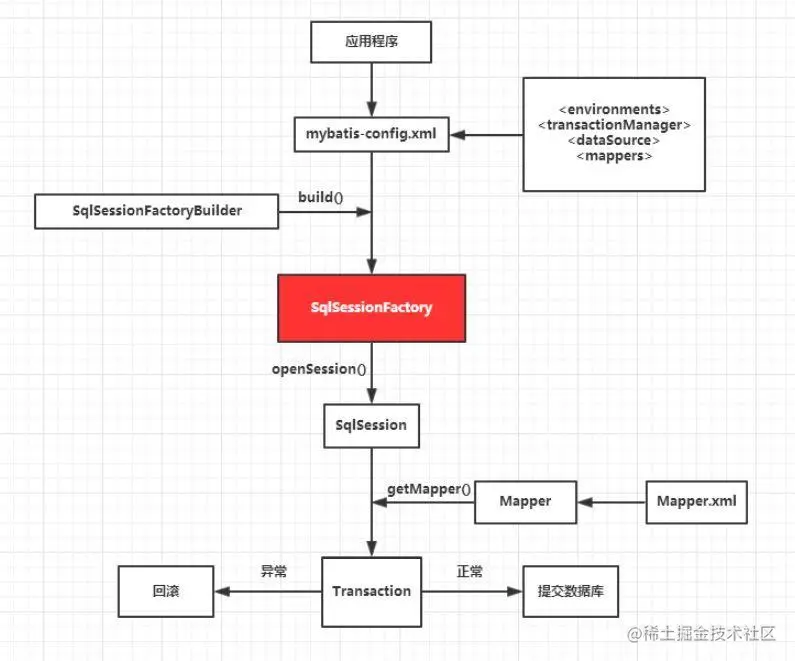
注意:当 Mybatis 与(Spring 等)依赖注入框架搭配使用时,SqlSession 实例将被直接创建并注入,不需用 SqlSessionFactoryBuilder 或 SqlSessionFactory。如 Mybatis-Spring。
- 通过
SqlSessionFactoryBuilder从mybatis-config.xml配置文件中构建出SqlSessionFactory; SqlSessionFactory开启一个SqlSession实例,(通过SqlSession实例)加载Mapper.xml文件获得Mapper对象并且运行Mapper映射的 SQL 语句;- 完成数据库的 CRUD 操作、和数据库事务提交,有异常则回滚,关闭
SqlSession。
MyBatis 的 XML 配置
了解
XML 配置文件(mybatis-config.xml):包含对 MyBatis 系统的核心设置,主要用于构建 SqlSessionFactory。
顶层配置元素 <configuration> 下的元素标签有:
-
<properties resource="org/mybatis/config.properties">=>SqlSessionFactoryBuilder.build()传入的属性:用于替换需动态配置的属性值; -
<settings>(设置):cacheEnabled、lazyLoadingEnabled延迟加载等; -
<typeAliases>(类型别名):给 Java 类型的全限定类名设置别名; -
<typeHandlers>(类型处理器):MyBatis 在设置(PreparedStatement)预处理语句中的参数或从结果集中取出一个值时, 将获取到的值以合适的方式转换成 Java 类型。枚举类型。 -
<objectFactory>(对象工厂):实例化目标类; -
<plugins>(插件):仅可编写针对ParameterHandler、ResultSetHandler、StatementHandler、Executor这 4 种接口的插件;-
MyBatis 用 JDK 的动态代理,为需拦截的接口生成代理对象,来实现接口方法拦截功能;每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是
InvocationHandler的invoke()方法。 -
实现 MyBatis 的
Interceptor接口并重写intercept()方法,给插件编写注解,指定要拦截哪个接口的哪些方法,在配置文件中配置编写的插件。
-
-
<environments>(环境配置):可配置多个环境,每个SqlSessionFactory实例选择一种环境。<environment>(环境变量)下有:<transactionManager>(事务管理器):决定事务作用域和控制方式;Spring 不必配置,会用自带的管理器来覆盖前面的配置。JDBC:直接用 JDBC 的提交和回滚功能,依赖从数据源获得的连接来管理事务作用域;在关闭连接时启用自动提交。MANAGED:从不提交或回滚一个连接,让容器来管理事务的整个生命周期(如 JEE 应用服务器的上下文)。
<dataSource>(数据源):获取数据库连接实例,连接池;UNPOOLED:每次请求时打开和关闭连接;POOLED:使用连接池,使并发 Web 应用快速响应请求;JNDI:在如 EJB 或应用服务器这类容器中用。
-
<databaseIdProvider>(数据库厂商标识) -
<mappers>(映射器)<mapper>:指定 XML 映射文件路径,包含 SQL 代码和映射定义信息。
SqlSessionFactoryBuilder 类
SqlSessionFactoryBuilder: 可从 XML 配置文件、注解或 Java Configuration 配置类来构建出 SqlSessionFactory 实例。一旦创建 ,就不再需要 Builder。
-
用 XML 配置文件构建
SqlSessionFactory实例:1
2
3
4
5
6
7
8// 用 Resources 工具类加载 mybatis-config.xml 文件,构造 InputStream 输入流实例 String resource = "org/mybatis/builder/mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); // env: 加载 environment 元素体中指定的环境,包括数据源和事务管理器,<environment id="dev"> // props: 读取作为方法参数传递的属性 SqlSessionFactory factory = builder.build(inputStream, [String env,] [Properties props]); -
注解;
-
用 Java 配置类
config/MyBatisConfig.java构建SqlSessionFactory实例:1
2
3
4
5
6
7@Configuration @EnableTransactionManagement @MapperScan({"com.macro.mall.mapper","com.macro.mall.dao"}) public class MyBatisConfig { } //SqlSessionFactory build(Configuration config)
SqlSessionFactory 类
SqlSessionFactory:用于创建、获取 SqlSession 实例,在应用的运行期间一直存在。
常用 openSession()方法来创建 SqlSession 实例,可选参数有:
ExecutorType枚举参数:用来设置语句执行,不复用 PreparedStatement 预处理语句,也不批量处理更新(包括插入和删除)语句。autoCommit事务处理:事务作用域开启(即不自动提交)。autoCommit=true表示自动提交(对很多数据库和 JDBC 驱动来说,等同关闭事务支持)。Connection数据库连接:由当前环境配置的 DataSource 实例中获取 Connection 对象。TransactionIsolationLevel事务隔离级别:用驱动或数据源的默认设置。MySQL InnoDB 引擎默认为不可重复读。
1 | |
Executor 执行器
指定ExecutorType 执行器类型:
- 可以在 MyBatis 配置文件中,指定默认的
ExecutorType执行器类型; - 也可以手动给
DefaultSqlSessionFactory的创建 SqlSession 的方法传递ExecutorType类型参数。
MyBatis 有三种基本的 Executor 执行器:
SimpleExecutor: 每执行一次 update 或 select,就开启一个 Statement 对象,用完立刻关闭 Statement 对象。ReuseExecutor: 执行 update 或 select,以 sql 作为 key 查找 Statement 对象,存在就使用,不存在就创建。- 简言之,就是重复使用 Statement 对象。
- 用完后不关闭 Statement 对象,而是放置于 Map<String, Statement>内,供下一次使用。
BatchExecutor:执行 update,将所有 sql 语句都 addBatch() 添加到批处理中,它缓存了多个 Statement 对象,每个 Statement 对象都是 addBatch() 完毕后,等待逐一执行 executeBatch() 批处理。- 使用
BatchExecutor完成批处理:addBatch()),等待统一执行 executeBatch()。 - 没有 select,JDBC 批处理不支持 select。
- 与 JDBC 批处理相同。
- 使用
作用范围:Executor 的这些特点,都严格限制在 SqlSession 生命周期范围内。
批处理
MyBatis 执行批量插入,能返回数据库主键列表吗?
JDBC 都能,MyBatis 当然也能。
XxxDao.java中:
1 | |
XxxDao.xml中:
1 | |
SqlSession 类
SqlSession:MyBatis 的核心处理类。不是线程安全的,因此不能被共享。包含:
- 所有执行语句的方法(在数据库执行 SQL 命令语句所需的所有方法,可直接执行已映射的 SQL 语句);
- 管理事务的方法;
- 及获取映射器实例的方法。
1 | |
映射器接口
映射器类/接口(DAO 层):XxxDao.java / XxxMapper.java,实现 Mapper 接口或由 @Mapper 修饰的类;映射器类/接口就是一个仅需声明与 SqlSession 方法(映射器方法)相匹配的接口。
- 映射器接口不需去实现任何接口或继承自任何类,只要方法签名可被用来唯一识别对应的映射语句即可。
- 映射器接口可继承自其他接口。在用 XML 绑定映射器接口时,保证语句处于合适的命名空间中即可。
- 字符串参数
ID无需匹配,而是由方法名匹配映射语句的ID。 - 返回类型必须匹配期望的结果类型,包括:原始类型、Map、POJO 和 JavaBean。
映射器类上的注解:
@Mapper:用于定义 Mybatis 映射器接口。告诉 Spring 框架此接口的实现类由 Mybatis 负责创建,并将其实现类对象装配到 Spring 容器中。不支持重载。@MapperScan(basePackages = {"com.macro.mall.mapper","com.macro.mall.dao"}):表示动态扫描指定包下的 mapper 接口,相当于每个 mapper 接口上都标注@Mapper。- (当 mapper 接口较多时),用于 Spring Boot 主启动类或 config/Java 配置类上,
- 见 SqlSessionFactoryBuilder 类。
Dao 接口
Mybatis 的 Dao 接口里的方法,参数不同时,方法可重载。
但是多个接口对应的映射必须只有一个,否则启动会报错。同一 xml namspace 下的 id 不允许重复。
重载需满足以下条件:
- 仅有一个无参方法和一个有参方法;
- 多个有参方法时,参数数量必须一致,且使用相同的
@Param,或使用param1这种。- id 相同,对应同一段
MappedStatement标签,用动态 SQL 的<if test="id != null">标签处理不同的参数列表来实现重载。
- id 相同,对应同一段
Dao 接口的工作原理
MyBatis 运行时会用 JDK 动态代理为 Dao 接口生成 proxy 代理对象,用于拦截接口方法,转而执行 MappedStatement 所代表的 SQL,返回 SQL 执行结果。
- 最佳实践中,通常一个 xml 映射文件,都会写一个 Dao 接口与之对应。
- 在 MyBatis 中,每一个
<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象。 - Dao 接口就是常说的
Mapper接口,- 接口的全限名,就是映射文件中的 namespace 的值,
- 接口的方法名,就是映射文件中
MappedStatement的 id 值,对应<select>等元素的id属性,是在命名空间中唯一的标识符,用来引用此语句; - 接口方法的参数,就是传递给 SQL 的参数。
Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个MappedStatement。- 举例:
com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到 namespace 为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。
Mybatis 版本 3.3.0:
1 | |
然后在 StuMapper.xml 中利用 Mybatis 的动态 sql 就可以实现。
1 | |
能正常运行,并能得到相应的结果,这样就实现了在 Dao 接口中写重载方法。
映射器接口实现/绑定
接口绑定 / 配置 Mapper 映射:Mybatis 实现了 mapper 映射器接口与 XML 映射文件的绑定,自动生成接口的具体实现,使用起来更省事和方便。
将映射器接口里的方法和 SQL 语句绑定,可直接调用接口方法;比起原来的 SqlSession 提供的方法、可更加灵活的选择和设置。
每个团队使用 MyBatis 方式还有不同,主要是如下:
注意,几种方式可以组合使用。
绑定实现方式
- 注解: 用来映射简单语句,代码更简洁。大多数情况下,并不推荐使用注解的方式编写 SQL :
- 注解中的 SQL 语句只能对应某一种数据库,与代码混编在一起。
- SQL 无法很好的排版;
- 会导致 Mapper 接口很长很乱;
- SQL 有变化时需重新编译代码。
-
XxxMapper.xml映射文件:用 XML 来映射复杂语句(如:嵌套联合语句映射)。与映射器接口同名,MyBatis 会自动查找并加载。最终使用 XML 的方式,因为 XML 便于可以看到每个表使用到的 SQL ,方便做优化和管理。
- 使用 MyBatis Generator (MBG) 。
- 在 Spring 配置文件中指定扫描映射文件的位置;
- 在
resources/mapper路径下,使用 MBG 创建UserMapper.xml文件。 - 在 MyBatis 配置文件中通过
<Mappers>指定位置。
MyBatisCodeHelper-Pro 插件。在没有使用 MyBatis-Plus 之前,使用过蛮长一段时间,我以前的老大也在用。- MyBatis-Plus:是一个
MyBatis的增强工具,在MyBatis的基础上只做增强不做改变,为简化开发、提高效率而生。- 提高开发效率:很多标准的数据库 CRUD 操作,编写还是比较枯燥乏味浪费时间,可以使用 MyBatis-Plus 简化。当然,一些相对复杂的 SQL ,还是会考虑使用 XML 。
- tkmybatis
- 使用 MyBatis Generator (MBG) 。
1 | |
占位符:#{} VS ${}
语句参数映射
#{}:是 SQL 的参数占位符,(预编译处理时 )MyBatis 会将其替换为 ?,在 SQL 执行前,调用JDBC中的PreparedStatement 的 set 参数设置方法,按序、安全地设置参数值。比如 ps.setInt(0, parameterValue)。
#{item.name}的取值方式为使用反射从参数对象中获取 item 对象的 name 属性值,相当于param.getItem().getName()。
-
自动进行 JDBC 类型转换,将传入的数据当作字符串,自动加双引号。
-
能很大程度防止 SQL 注入,故优先用
#{}。- SQL注入发生在编译过程中,因为注入了某些特殊字符,最后被编译成了恶意的执行操作;
- 而预编译机制可以很好的防止 SQL 注入。预编译完成后,SQL 的结构已经固定,即便用户输入非法参数,也不会对 SQL 的结构产生影响,从而避免了潜在的安全风险。
-
一般用来传字段名;传多个参数时,参数名必须对应与当前表关联
[实体类的属性名]或[Map集合关键字]。1
2
3
4
5
6
7
8
9
10// 语句接收一个 int(或 Integer)类型的参数,返回 HashMap 类型的对象 <select id="selectPerson" parameterType=”int“ resultType=”hashmap“> SELECT * FROM person WHERE ID = #{id} </select> // 基本等价于 JDBC 代码: // #{id},告诉 MyBatis 创建一个预处理语句的参数,在JDBC中由 `?` 来标识 String selectPerson = ”SELECT * FROM PERSON WHERE ID=?“; PreparedStatement ps = conn.prepareStatement(selectPerson); ps.setInt(1, id); // 向预处理语句传参
${}:是 Properties 文件中的变量占位符,可以用于标签属性值和 sql 内部,属于静态文本替换。比如 ${driver} 会被静态替换为 com.mysql.jdbc.Driver。
- 不自动进行 JDBC 类型转换,将传入的数据直接显式地生成在 SQL 中,不加双引号。
- 在
JDBC不支持用#{}占位符的地方,只能用${}。- 如用
order/group by ${colName}排序、分组的动态参数,在 SQL 语句中直接插入,不会修改或转义字符串。#{}会自动加双引号,出现order by "id"的错误。 - 可用于标签属性值和 SQL 内部。
- 如用
- 一般用于传入数据库对象,如传入表名。
一、全注解方式(不推荐)
在映射器类中用注解标识 SqlSession 方法:
@Select
同
@Insert、@Update、@Delete
@Select:用于方法上,对应 XML 中的 <select> 标签。
@Param:声明变量名、给参数命名。用于向映射器(通过动态 SQL 参数占位符#{}、变量占位符${})传参。是为SQL语句中参数赋值而服务的。- 在方法为单参数时,非必须。在方法有两个或以上的参数时,必须要加,不然 Mybatis 识别不了。
- 比如在mapper里面某方法添加注解后,
findUserByName(@Param("userId") int id)。通过#{userId}将参数值传入SQL语句中(给SQL的参数赋值)。 - 通常,禁止使用 Map 作为查询参数,因为无法通过方法的定义,很直观的看懂具体的用途。
@ResultType:返回类型是 void 时,用结果处理器;@ResultMap:指定 XML 映射文件中<resultMap>元素的 id。
1 | |
返回值处理
SQL 查询的返回值可以是单个对象、多个对象的列表或简单的原始类型(如 int、String 等)。
-
单个对象:
1
2@Select("SELECT * FROM users WHERE id = #{id}") User selectById(@Param("id") Integer id); -
列表:
1
2@Select("SELECT * FROM users") List<User> selectAll(); -
原始类型:
1
2@Select("SELECT COUNT(*) FROM users") int countUsers();
二、XML 映射文件
可理解为 mapper 接口实现类的地位,相当于注解 @Select、@Update 等中的 SQL 语句。
映射文件中的顶级元素
<mapper namespace="com.macro.mall.dao.UmsRoleDao">:(用 XML 绑定映射器接口时),namespace 属性是该 XML 对应的 mapper 接口的全限定名。
SQL 映射文件的顶级元素(按照应被定义的顺序):
<cache>:命名空间的缓存配置。- MyBatis 的缓存分为一级缓存和二级缓存,一级缓存放在 session 里,默认就有;
- 二级缓存放在它的命名空间里,默认是打开的,使用二级缓存属性类需实现
Serializable序列化接口(可用来保存对象的状态),通过<cache>配置。
<cache-ref>:引用其他命名空间的缓存配置。<resultMap>:描述如何从数据库结果集中加载对象。逐一定义数据库表的列名column**和 **model对象的属性名间的映射关系。<parameterMap>– 老式风格的参数映射。已废弃,现用行内参数映射 parameterType属性。<sql id="Base_Column_List">:可被其他语句引用的可重用语句块。比如基本字段列表部分。(在加载阶段)参数可静态地确定下来。trim|where|set|foreach|if|choose|when|otherwise|bind等;
<include>:用于引入sql片段;- 被引用的 B 标签依然可以定义在任何地方,MyBatis 都可以正确识别。
- 原理是,MyBatis 解析 A 标签,发现 A 标签引用了 B 标签,但是 B 标签尚未解析到,此时 MyBatis 会将 A 标签标记为未解析状态,然后继续解析余下的标签,待所有标签解析完毕,MyBatis 会重新解析那些被标记为未解析的标签,此时再解析 A 标签时,B 标签已经存在,A 标签也就可以正常解析完成了。
<select id="selectByExample"> </select>:映射查询语句- 通过
resultType属性的值查找 map 等基础类型、或 [<mapper>的namespace属性值,即映射器类的全限定名,省略表示本文件的 ] +<resultType>的id; - 语句参数映射:如果 User 类型的参数对象传递到了语句中,会查找 id、username 属性,将值传入预处理语句的参数中。
- 常见属性见后续。
- 通过
<insert> </insert>:映射插入语句<selectKey></selectKey>
<update>:映射更新语句<delete>:映射删除语句
UserMapper.xml 示例
- 建议 1 :对于绝大多数查询,返回统一字段,所以可以使用
<sql />标签,定义 SQL 段。对于性能或者查询字段比较大的查询,按需要的字段查询。 - 建议 2 :对于数据库的关键字,使用大写。例如说,
SELECT、WHERE等等。 - 建议 3 :基本是每“块”数据库关键字占用一行。一定要排版干净。
1 | |
将 sql 执行结果封装为目标对象并返回
- 第一种是使用
<resultMap>标签,逐一定义列名和对象属性名之间的映射关系。 - 第二种是使用 sql 列的别名功能,将列别名书写为对象属性名。
- 比如 T_NAME AS NAME,对象属性名一般是小写 name,但是列名不区分大小写,MyBatis 会忽略列名大小写,智能找到与之对应对象属性名。
有了列名与属性名的映射关系后,MyBatis 通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回。那些找不到映射关系的属性,是无法完成赋值的。
<resultMap> 元素
最复杂也最强大的元素。
<resultMap> 元素:描述如何从数据库结果集中加载对象。逐一定义数据库表的列名column **和 **model JavaBean 对象的属性名间的映射关系。
包括的子标签有:
<constructor>:用于在实例化类时,注入结果到构造方法中;- Executor 执行器:见 SqlSessionFactory 类,使用
BatchExecutor执行器完成批处理。 typeHandlers类型处理器:处理枚举类型;
- Executor 执行器:见 SqlSessionFactory 类,使用
<id column="id" jdbcType="BIGINT" property="id" />:指定唯一确定一条记录的 id 列。标记作为 id 主键字段的结果,可帮助提高整体性能;<result />:注入到字段或 JavaBean 属性的普通结果;用于设置数据库表的column列名、jdbcType、(JavaBean 实体类中的)property属性名;- 实体类中的属性名和表中的字段名不一致时的解决方案?
- 一对多怎么实现?
<association>: 一个复杂类型的关联;许多结果将包装成这种类型;- 嵌套结果映射 – 可关联
resultMap元素,或是对其它结果映射的引用; - 延迟加载
- 嵌套结果映射 – 可关联
<collection />:一个复杂类型的集合;- 嵌套结果映射 – 集合可是
resultMap元素,或是对其它结果映射的引用;
- 嵌套结果映射 – 集合可是
<discriminator>– 歧视者,用结果值来决定使用哪个resultMap;
1 | |
typeHandlers 类型处理器
typeHandlers类型处理器映射 Enum 枚举类?
MyBatis 可以映射枚举类,不单可以映射枚举类,MyBatis 可以映射任何对象到表的一列上。
映射方式为自定义一个 TypeHandler ,实现 TypeHandler 的 setParameter() 和 getResult() 接口方法。 TypeHandler 有两个作用:
- 一是完成从 javaType 至 jdbcType 的转换;
- 二是完成 jdbcType 至 javaType 的转换,体现为
setParameter()和getResult()两个方法,分别代表设置 sql 问号占位符参数和获取列查询结果。
实体类属性名和表字段名不一致
实体类中的属性名和表中的字段名不一致时的解决方案:
-
通过在查询的 SQL 语句中定义字段名的别名;
-
通过
<resultMap>来映射字段名和实体类属性名的一一对应关系。
一对多的关联查询
MyBatis 能执行一对多的关联查询吗?
都有哪些实现方式,以及它们之间的区别。
能,MyBatis 不仅可以执行一对一、一对多的关联查询,还可以执行多对一,多对多的关联查询,
- 多对一查询,其实就是一对一查询,只需要把
selectOne()修改为selectList()即可; - 多对多查询,其实就是一对多查询,只需要把
selectOne()修改为selectList()即可。
关联对象查询,有两种实现方式:
- 一种是单独发送一个 sql 去查询关联对象,赋给主对象,然后返回主对象。
- 另一种是使用嵌套查询,即使用 join 查询,一部分列是 A 对象的属性值,另外一部分列是关联对象 B 的属性值。
- 好处:只发一个 sql 查询,就可以把主对象和其关联对象查出来。
1 | |
那么问题来了,join 查询出来 100 条记录,如何确定主对象是 5 个,而不是 100 个?
- 其去重复的原理是:
<resultMap>标签内的<id>子标签,指定了唯一确定一条记录的 id 列,MyBatis 根据<id>列值来完成 100 条记录的去重复功能。<id>可以有多个,代表了联合主键的语意。
- 同样主对象的关联对象,也是根据这个原理去重复的,尽管一般情况下,只有主对象会有重复记录,关联对象一般不会重复。
举例:下面 join 查询出来 3 条记录,一、二列是 Teacher 对象列,第三列为 Student 对象列,MyBatis 去重复处理后,结果为 1 个老师 3 个学生,而不是 3 个老师 3 个学生。
| t_id | t_name | s_id |
|---|---|---|
| 1 | teacher | 38 |
| 1 | teacher | 39 |
| 1 | teacher | 40 |
延迟加载
是否支持延迟加载及实现原理?
MyBatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载。
- association 指的就是一对一,
- collection 指的就是一对多查询。
在 MyBatis 配置文件中,可以配置是否启用延迟加载 lazyLoadingEnabled=true|false。
实现原理
原理是:使用 CGLIB 创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,
- 比如调用
a.getB().getName(),拦截器invoke()方法发现a.getB()是 null 值, - 那么就会单独发送事先保存好的查询关联 B 对象的 sql,把 B 查询上来,
- 然后调用 a.setB(b),于是 a 的对象 b 属性就有值了,
- 接着完成
a.getB().getName()方法的调用。这就是延迟加载的基本原理。
当然不光是 MyBatis,几乎所有的包括 Hibernate,支持延迟加载的原理都是一样的。
<select> 元素
<select> 元素的属性有:
id:在命名空间中唯一的标识符,用来引用此语句。对应 DAO 接口中的方法名,方法参数就是传递给 SQL 的参数。parameterType:参数类的完全限定名或别名。MyBatis 可通过 TypeHandler 推断出具体传入语句的参数,默认值为 unset。resultType:返回值类型,类的完全限定名或别名。如果是集合,应是集合包含的类型,而不是List。- MyBatis 会在幕后自动创建一个
ResultMap,再根据属性名来映射列到 JavaBean 的属性上。如果列名和属性名不能匹配上,可在select语句中设置列别名来完成匹配。
- MyBatis 会在幕后自动创建一个
resultMap:指定外部 resultMap 的命名(id)引用。flushCache: true 表示任何时候只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:false。useCache: true 表示本条语句的结果被二级缓存,默认值:select 元素为 true。timeout:在抛出异常前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)。fetchSize:驱动程序每次批量返回的结果行数。默认值为 unset(依赖驱动)。statementType:STATEMENT,PREPARED 或 CALLABLE ,让 MyBatis 分别用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。resultSetType:FORWARD_ONLY,SCROLL_SENSITIVE 或 SCROLL_INSENSITIVE,默认值为 unset (依赖驱动)。databaseId:如果配置了 databaseIdProvider,MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带或不带的语句都有,则忽略不带的。resultOrdered:仅针对嵌套结果 select 语句适用: true,假设包含了嵌套结果集或分组,当返回一个主结果行时,就不会有对前面结果集引用的情况。使得在获取嵌套的结果集时不至于导致内存不够用。默认值:false。resultSets:仅对多结果集的情况适用,将列出语句执行后返回的结果集并每个结果集给一个名称,用逗号分隔。
1 | |
id 属性
不同的 xml 映射文件,id 是否可以重复?
下面那些顶级元素的 id 属性是否可重复:
- 本文件内 id 不可重复;
- 不同的 xml 映射文件,如果配置了 namespace,那么 id 可以重复;
- 如果没有配置 namespace,那么 id 不能重复;
- 毕竟 namespace 不是必须的,只是最佳实践而已。
原因:就是 namespace+id 是作为 Map<String, MappedStatement> 的 key 使用的,如果没有 namespace,就剩下 id,那么 id 重复会导致数据互相覆盖。有了 namespace,自然 id 就可以重复。
<insert> <update> 元素
仅对 insert 和 update 有用的属性:
useGeneratedKeys:MyBatis 使用 JDBC 的getGeneratedKeys()方法来取出由数据库内部生成的主键(如:MySQL 和 SQL Server 等关系数据库管理系统的自动递增字段),默认值:false。<selectKey>:不支持自增的主键生成策略标签;keyColumn
<selectKey>
在 MySQL 中用函数来自动生成插入表的主键,而且需方法返回这个生成主键,如用 MyBatis 的 <selectKey> 标签。
是为了解决 insert 数据时不支持主键自动生成的问题,可很随意的设置生成主键的方式。
尽量不用,很麻烦。
<selectKey> :不支持自增的主键生成策略标签
keyProperty:selectKey 语句结果应被设置的目标属性。用于主键回填,将自增长的主键设置为LAST_INSERT_ID()的返回值;打印新插入记录的 id。- 唯一标记一个属性,MyBatis 会通过
getGeneratedKeys()的返回值或通过 insert 语句的<selectKey>子元素设置它的键值,默认:unset。 - 可传入参数,如:
LAST_INSERT_ID(10)则返回10; - 用一条 INSERT 语句插入多行时,只返回插入第一行数据时的 id,原因是这使依靠其它服务器复制同样的 INSERT语句变得简单。
- 唯一标记一个属性,MyBatis 会通过
order = "AFTER":表示先执行insert标签内的插入语句,后执行本标签内的select last_insert_id()语句;resultType:结果的类型;statementType。
1 | |
Mybatis Generator
见 SSM 分层目录中的
mall-mbg/src/main/。
依赖
pom.xml
1 | |
配置生成器
mall-mbg/src/main/resources/generatorConfig.xml;详细代码见下。
- 通过
generator.properties和<jdbcConnection>配置 JDBC 数据库连接的参数(driverClass、connectionURL、userId、 password); <javaModelGenerator targetPackage="" targetProject=""/>:Java 模型创建器,生成model实体类,与数据库表一一对映;<javaClientGenerator targetPackage="" targetProject=""/>:生成Mapper接口;<sqlMapGenerator targetPackage="" targetProject=""/>:mapper.xml 文件生成器,实现mapper接口CRUD单表查询。<commentGenerator type="com.macro.mall.CommentGenerator">标签:指定添加 Swagger 注解、注释等。- 通过配置 MyBatis Generator 的插件自动生成
toString()、Equals()、Hashcode()方法;
参考配置
1 | |
运行
运行程序入口 Generator 类的 main 函数,生成代码。如果使用 Maven,可以通过 MyBatis Generator Maven 插件来运行。
1 | |
tkMyBatis
tkmybatis 对自己的定位是 mybatis 的工具的意思,那么 tk 猜测是 toolkit 的缩写。也因此,tkmybatis 是多个开源项目组合起来的:
- Mapper :提供通用的 MyBatis Mapper 。
- Mybatis-PageHelper :提供 MyBatis 分页插件。
动态 SQL
目的:在 XML 映射文件内,以标签的形式编写动态 SQL,用于进行逻辑判断和动态拼接 SQL 语句。
执行原理:使用 OGNL 从 SQL 参数对象中计算表达式的值,再动态拼接 SQL。
MyBatis 提供了 9 种动态 sql 标签:
<if></if><where></where>(trim,set)<choose></choose>(when, otherwise)<foreach></foreach><bind/>
标签种类:
-
<if> </if>:动态 SQL 最常见情景是根据(@param传入的方法参数作为)条件判断,并拼接到 where 子句;1
2
3<if test="queryParam.createTime != null and queryParam.createTime != '' "> AND create_time LIKE concat(#{queryParam.createTime},”%”) </if> -
<trim> (<where>, <set>);-
prefix在当前位置要添加的前缀; -
suffix在当前位置要添加的后缀; -
prefixOverrides语句前面部分要去掉的的内容; -
suffixOverrides语句后面部分要去掉的的内容。1
2
3
4
5
6
7insert into pms_member_price <trim prefix="(" suffix=")" suffixOverrides=","> <if test="productId != null"> product_id, #{productId,jdbcType=BIGINT}, </if> </trim> </insert>
-
-
<choose> (<when>, <otherwise>):同<switch>; -
<foreach>:1
2
3<foreach item="item" index="index" collection="list" open="ID in (" separator="," close=")" nullable="true"> #{item} </foreach> -
<bind>:允许在 OGNL 表达式外创建一个变量,并绑定到当前的上下文; -
<script>
SQL 语句构建器:通过 SQL 工具类处理动态 SQL 典型问题,如加号、引号、换行、格式化问题、嵌入条件的逗号管理及 AND 连接。
1 | |
Example 类
Example类:使用Example类进行SQL语句中的where条件语句设置,相当于where后面的部分,包括条件查询、排序、去重等功能。可以根据不同的条件来查询和操作数据库,简化书写sql的过程。
- 理论上通过example类可以构造任何筛选条件。
在mybatis-generator中加以配置,配置数据表的生成操作就可以自动生成example了。
- 会为每个字段产生Criterion,为底层的mapper.xml创建动态 SQL。
常见用法:
Example 类的生成
在generatorConfig.xml 配置文件中,用表名生成对应的实体类时,生成Example的信息默认为true。
1 | |
example 方法
比如example是根据user表生成的,UserMapper属于dao层,UserMapper.xml是对应的映射文件。
Mapper 接口中的方法、及example 方法有:
- String/Integer insert(User record):插入数据(返回值为ID)
- int deleteByPrimaryKey(Integer id):按主键删除
int
deleteByExample(UserExampleexample):按条件删除 - int updateByPrimaryKey(User record):按主键更新
int updateByPrimaryKeySelective(User record):按主键更新值不为null的字段
int
updateByExample(User record,UserExampleexample):按条件更新 intupdateByExampleSelective(User record,UserExampleexample):按条件更新值不为null的字段 - int
countByExample(UserExampleexample):按条件计数 - User selectByPrimaryKey(Integer id):按主键查询
List
selectByExample(UserExampleexample):按条件查询 ListselectByExampleWithBLOGs(UserExampleexample):按条件查询(包括BLOB字段)。只有当数据表中的字段类型有为二进制的才会产生。
selectByExample
Example用于添加条件,相当于where后的部分。
selectByExample几乎可以解决所有的查询,select和selectByPrimaryKey是简化的针对特定情况的解决方法。
- 当有主键时,优先用
selectByPrimaryKey, - 当根据实体类属性查询时用
select, - 当有复杂查询时,如模糊查询、条件判断、条件组合时,使用
selectByExample。
1 | |
xxxSelective()
updateByPrimaryKeySelective() 和 updateByPrimaryKey() 的区别:
updateByPrimaryKeySelective():更新非空字段;- ` updateByPrimaryKey()`:全字段更新,包括将空字段设为NULL。
Example 对象
Example 类的成员变量
属性:
orderByClause:用于指定ORDER BY条件。这个条件没有构造方法,直接通过传递字符串值指定。distinct:用来指定是否要去重查询的,true为去重。oredCriteria:是用来指定查询条件的。
static 内部类 Criteria():主要是定义 SQL 语 句where后的查询条件。
- Criterion是最基本的Where条件,针对字段进行筛选。
Example 类的成员方法
example 用于添加条件,相当于where后面的部分,理论上单表的任何复杂条件查询都可以使用example来完成。
example实例方法:
- example.
setOrderByClause(“字段名 ASC”); 添加升序排列条件,DESC为降序。 example.setDistinct(false) 去除重复,boolean型,true为选择不重复的记录。 - example.and(Criteria criteria) 为example添加criteria查询条件,关系为与。 example.or(Criteria criteria) 为example添加criteria查询条件,关系为或。
example.createCriteria()或者or()创建 Criteria 对象。
criteria 方法:
- criteria.andXxxIsNull 添加字段xxx为null的条件 criteria.andXxxIsNotNull 添加字段xxx不为null的条件
- criteria.andXxxEqualTo(value) 添加xxx字段等于value条件 criteria.andXxxNotEqualTo(value) 添加xxx字段不等于value条件 criteria.andXxxGreaterThan(value) 添加xxx字段大于value条件 criteria.andXxxGreaterThanOrEqualTo(value) 添加xxx字段大于等于value条件 criteria.andXxxLessThan(value) 添加xxx字段小于value条件 criteria.andXxxLessThanOrEqualTo(value) 添加xxx字段小于等于value条件
- criteria.andXxxIn(List<?>) 添加xxx字段值在List<?>条件 criteria.andXxxNotIn(List<?>) 添加xxx字段值不在List<?>条件
- criteria.
andXxxLike(“%”+value+”%”) 添加xxx字段值为value的模糊查询条件 criteria.andXxxNotLike(“%”+value+”%”) 添加xxx字段值不为value的模糊查询条件 - criteria.andXxxBetween(value1,value2) 添加xxx字段值在value1和value2之间条件 criteria.andXxxNotBetween(value1,value2) 添加xxx字段值不在value1和value2之间条件
1 | |
参考代码:
分页
MyBatis 是如何进行分页的?分页插件的原理是什么?
MyBatis 用 RowBounds 对象进行分页,是针对 ResultSet 结果集执行的内存分页,而非物理分页;
物理分页的实现方式:
- 在 SQL 内直接书写带有物理分页的参数
limit offset; - 用分页插件:基本原理是用 MyBatis 提供的插件接口,实现自定义插件,在插件的拦截方法内拦截并重写待执行的 SQL,根据 dialect 方言,添加对应的物理分页语句和参数。
举例: select _ from student ,拦截 sql 后重写为: select t._ from (select \* from student)t limit 0,10。
一、PageHelper 分页
MyBatis 物理分页插件。SpringBoot 整合 PagerHelper 就自动整合了 MyBatis。
Mybatis分页,借助 PageHelper工具来实现:
PageHelper.startPage和PageHelper.clearPage中间是需要分页的业务查询代码,- 可以通过
PageInfo对象包装,获取其中需要的分页参数返回给前端展示.
1 | |
二、JPA 的 Pageable 分页
Spring Data JPA 通过定义 Pageable 对象来处理分页功能:封装了分页的参数、当前页、每页显示的条数。
- 其中
PageRequest来定义分页参数, Page对象来接收查询结果进行分页包装,- 包装后的结果
pageResult可以得到总记录数、总页数、分页列表等数据结果。
Pageable pageable = PageRequest.of(pageNum, pageSize);
Page 是一个泛型接口,代表查询的单页结果集等信息,常用以下方法:
int getTotalPages() //返回总的页数
long getTotalElements() //返回总行数
List<T> getContent() //返回查询结果集的List
Pageable 接口常常用于构造翻页查询,通常也有以下方法:
int getPageNumber() //获取总页数
int getPageSize() //获取一页的行数
Pageable next() //返回Pageable类型的下一页
boolean hasPrevious() //是否有上一页
PageRequest 是 Pageable 的实现类。用于构造分页查询需要的页码(从0开始)、每页行数、排序等,有如下构造方法:
public static PageRequest(int page,int siez)
public static PageRequest(int page,int size,Sort sort)
PageImpl 是 Page 的实现类,可以由 List 和其他参数构造一个 PageImpl 对象。
1 | |
Sort 是一个用于排序的类型,默认升序排序,通常有以下用法:
1 | |
三、Hutools 分页
引入hutools工具类,使用其中的PageUtil和CollUtil工具类来实现。
- 因为在较复杂的查询业务中,前两种实现起来很费劲还容易写错,不仅可能牵扯到多个类及方法,写完后过段时间也不容易阅读。
- 而Hutools分页就类似于很早以前的分页方式,可理解为绿色简易版JSP分页,只需在服务层使用一个工具类分页即可。
- 既灵活又便于阅读,简直是分页的神器。