摘要:用于将用户请求(根据负载均衡算法)分配、转发到多台服务器(集群)处理,以提高系统整体的并发处理能力和可靠性(高可用)。
目录
[TOC]
负载均衡
高并发首选方案就是集群化部署,一台服务器承载的QPS有限,多台服务器叠加能应对高并发。
此时就需要负载均衡。
负载均衡:用于将用户请求(根据负载均衡算法)分配、转发到多台服务器(集群)处理,以提高系统整体的并发处理能力和可靠性(高可用)。
- 负载均衡器运行过程、核心的职责包含两个部分:
- 选择谁来处理用户请求:即根据负载均衡算法得到转发的节点;
- 将用户请求转发过去。
- 高可用:当某个节点故障时,负载均衡器会将用户请求转发到另外的节点上,从而保证所有服务持续可用。
经常无差别混用负载均衡器(load balancer)和代理(proxy),一般认为二者整体上对等。但严格地讲,并非所有代理都是负载均衡器,但绝大多数代理都有负载均衡功能。
负载均衡器的功能:
服务发现:系统中哪些后端可用、它们的地址是什么(负载均衡器如何能够联系上它们)。健康检查:哪些后端是健康的,可以正常接收请求。负载均衡:用哪种算法来均衡请求至健康的后端。
使用场景:
- 集群
- DNS
- CDN:GSLB 全局负载均衡
常见的负载均衡算法
总结
常用的负载均衡算法有:随机法(两次随机法)、轮询(加权轮询)、最小连接(加权最小连接)、最少活跃法、最快响应时间法、源地址哈希法(一致性哈希法)。
- 随机算法:把请求随机发送到某台服务器上。
- 缺点:分配不公平,可能会导致某些服务器过载,而某些服务器空闲。部分机器在一段时间之内都无法被随机到。
- 两次随机法:在随机法的基础上改进、多增加了一次随机,多选出一个服务器。再根据两台服务器的负载等情况,从其中选择出一个最合适的服务器。好处是:可以动态地调节后端节点的负载,使其更加均衡。
- 轮询算法:把每个请求轮流发送到每个服务器上,解决了分配不公平的问题。适合每个服务器的性能差不多的场景。
- 缺点:如果服务器性能存在差异的情况下,那么性能较差的服务器可能无法承担过大的负载。
- 加权轮询:在轮询的基础上,根据服务器的性能差异,为服务器赋予一定的权值,性能高的服务器分配更高的权值。
- 二者共有的缺点:每个请求的连接时间不一样造成的负载不均衡问题。kafka 都只考虑 Partition 的负载,而没有考虑 Consumer 的负载。
-
最少连接算法:将请求发送给当前最少连接数的服务器上。解决每个请求的连接时间不一样造成的负载不均衡的问题。
- 加权最少连接:在最少连接的基础上,根据服务器的性能为每台服务器分配权重,再根据权重计算出每台服务器能处理的连接数。
-
最少活跃法:以活动连接数为标准,可以理解为当前正在处理的请求数。活跃数越低,说明处理能力越强,这样就可以使处理能力强的服务器处理更多请求。相同活跃数的情况下,可以进行加权随机。
- 和最小连接法类似,但要更科学一些。
- 最快响应时间法:以响应时间为标准来选择具体是哪一台服务器处理。客户端会维持每个服务器的响应时间,每次请求挑选响应时间最短的。相同响应时间的情况下,可以进行加权随机。
- 可以使得请求被更快处理,但可能会造成流量过于集中于高性能服务器的问题。
-
源地址哈希法:通过对客户端 IP 计算哈希值之后,再对服务器数量取模得到目标服务器的序号。
-
可以保证同一 IP 的客户端的请求都转发到同一台服务器上,用来实现会话粘滞(Sticky Session)。
- 常规哈希法的缺点:在服务器数量变化(增减)时,
hash(key) % N中 N 变了,导致计算出的哈希值会更新、重新落在不同的服务器上。 - 一致性哈希法:将数据和节点都映射到一个哈希环上,根据顺时针查找哈希值的顺序来确定数据属于哪个节点。当服务器增加或删除时,只影响该服务器的哈希,而不会导致整个服务集群的哈希键值重新分布。
- 新增、删除节点时:只会影响节点与前一个节点(新增节点逆时针查找的第一个节点)之间的数据。
- 虚拟节点:作用在于让环上的节点区间分布粒度变细。用于解决环上的节点数量非常少、可能造成数据分布不平衡的问题。
- 目的地址哈希调度:
-
随机算法
随机算法(Random):把请求随机发送到服务器上。适合服务器性能差不多的场景。
比较明显的缺陷:即使是大家权重一样,部分机器在一段时间之内无法被随机到。
两次随机法:在随机法的基础上多增加了一次随机,多选出一个服务器。随后再根据两台服务器的负载等情况,从其中选择出一个最合适的服务器。
- 好处是:可以动态地调节后端节点的负载,使其更加均衡。如果只使用一次随机法,可能会导致某些服务器过载,而某些服务器空闲。
轮询
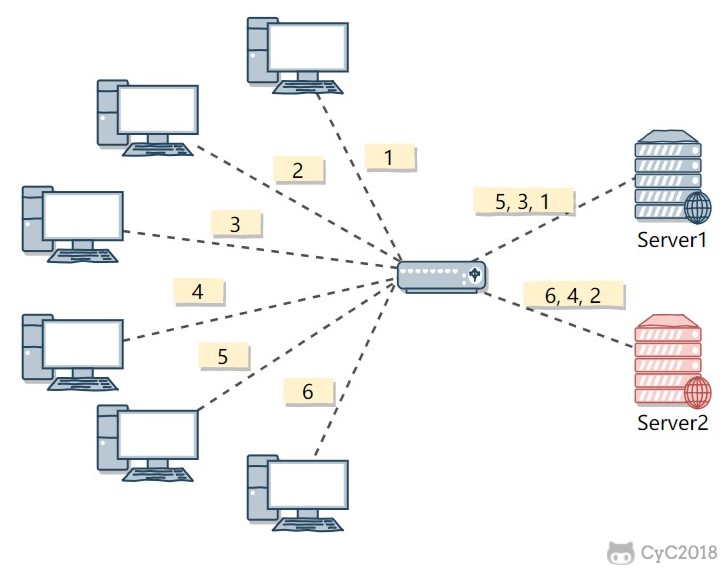
轮询算法(Round Robin):把每个请求轮流发送到每个服务器上。
- 该算法比较适合每个服务器的性能差不多的场景,如果有性能存在差异的情况下,那么性能较差的服务器可能无法承担过大的负载(下图的 Server 2)。
下图中,一共有 6 个客户端产生了 6 个请求,这 6 个请求按 (1, 2, 3, 4, 5, 6) 的顺序轮流发送到两个服务器。
- (1, 3, 5) 的请求会被发送到服务器 1,
- (2, 4, 6) 的请求会被发送到服务器 2。
加权轮询
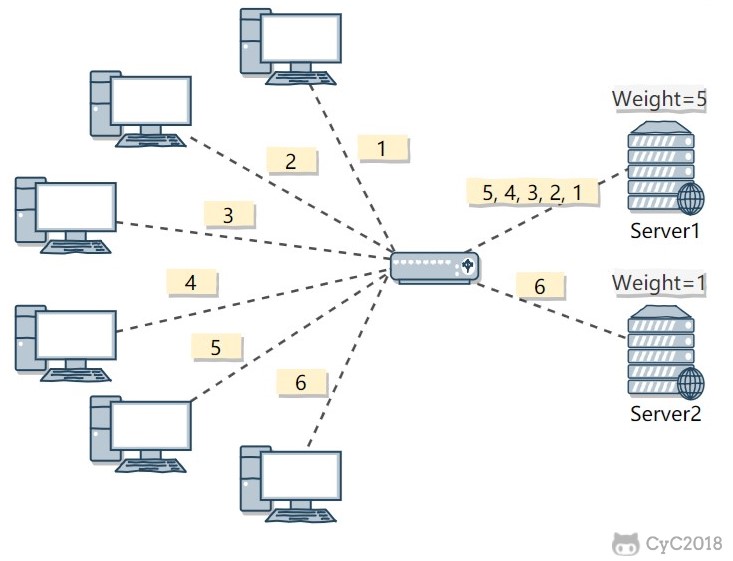
加权轮询(Weighted Round Robbin):是在轮询的基础上,根据服务器的性能差异,为服务器赋予一定的权值,性能高的服务器分配更高的权值。
例如上图中,服务器 1 被赋予的权值为 5,服务器 2 被赋予的权值为 1,那么 (1, 2, 3, 4, 5) 请求会被发送到服务器 1,(6) 请求会被发送到服务器 2。
在加权轮询的基础上,还有进一步改进得到的负载均衡算法,比如平滑的加权轮训算法。
最少连接
由于每个请求的连接时间不一样,使用轮询或者加权轮询算法的话,可能会让一台服务器当前连接数过大,而另一台服务器的连接过小,造成负载不均衡。
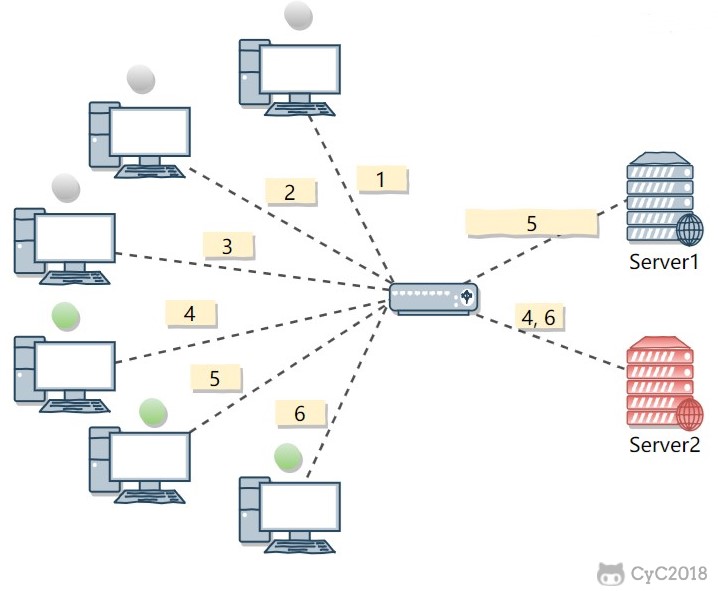
例如下图中,
- (1, 3, 5) 请求会被发送到服务器 1,但是 (1, 3) 很快就断开连接,此时只有 (5) 请求连接服务器 1;
- (2, 4, 6) 请求被发送到服务器 2,只有 (2) 的连接断开,此时 (6, 4) 请求连接服务器 2。该系统继续运行时,服务器 2 会承担过大的负载。
最少连接算法(least Connections):将请求发送给当前最少连接数的服务器上。
例如下图中,服务器 1 当前连接数最小,那么新到来的请求 6 就会被发送到服务器 1 上。
加权最少连接
加权最少连接(Weighted Least Connection):在最少连接的基础上,根据服务器的性能为每台服务器分配权重,再根据权重计算出每台服务器能处理的连接数。
最少活跃法
和最小连接法类似,但要更科学一些。
最少活跃法:以活动连接数为标准,活动连接数可以理解为当前正在处理的请求数。活跃数越低,说明处理能力越强,这样就可以使处理能力强的服务器处理更多请求。相同活跃数的情况下,可以进行加权随机。
最快响应时间法
不同于最小连接法和最少活跃法
最快响应时间法:以响应时间为标准来选择具体是哪一台服务器处理。客户端会维持每个服务器的响应时间,每次请求挑选响应时间最短的。相同响应时间的情况下,可以进行加权随机。
这种算法可以使得请求被更快处理,但可能会造成流量过于集中于高性能服务器的问题。
源地址哈希法
源地址哈希(IP Hash):通过对客户端 IP 计算哈希值之后,再对服务器数量取模得到目标服务器的序号。
- 可以保证同一 IP 的客户端的请求、同一个用户的请求会转发到同一台服务器上,用来实现会话粘滞(Sticky Session)。
一致性哈希法
和哈希法类似,一致性 Hash 法也可以让相同参数的请求总是发到同一台服务器处理。
本质上也是一种取模算法。不过,不同于按服务器数量取模,一致性hash是对固定值 2^{32} 取模。
另外,见分库分表中水平分表的一致性哈希分片算法。
常规哈希法的缺点:在服务器数量变化(增减)时,hash(key) % N 中 N 变了,导致计算出的哈希值会更新、重新落在不同的服务器上。
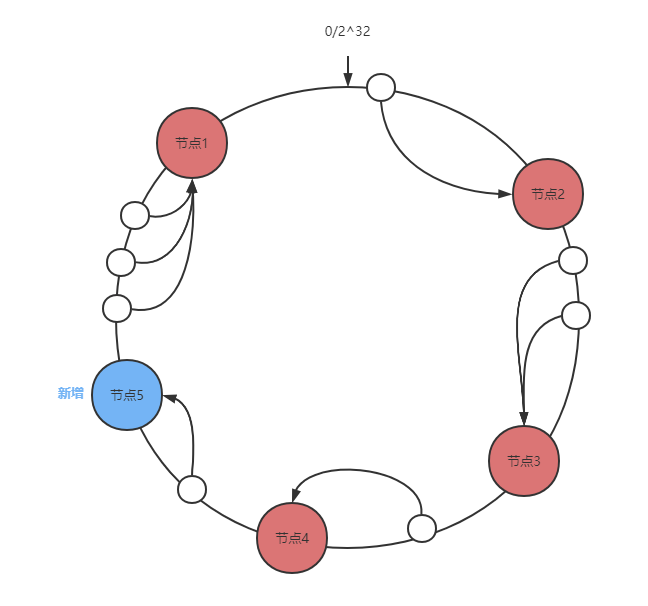
而一致性哈希法的核心思想是:将数据和节点都映射到一个哈希环上,根据顺时针查找哈希值的顺序来确定数据属于哪个节点。当服务器增加或删除时,只影响该服务器的哈希,而不会导致整个服务集群的哈希键值重新分布。
- 将整个哈希值空间(固定值 2^{32})按照顺时针方向首尾连接组织成一个虚拟的圆环,称为 Hash 环;
- 首先对节点进行哈希计算,(具体可以选择服务器的IP或主机名作为关键字),从而确定每台机器在哈希环上的位置。哈希值通常在 2^32-1 范围内。
- 当要查询 key 的目标节点时,对 key 使用相同的函数进行哈希计算,并确定此数据在环上的位置,然后顺时针查找到的第一个节点就是目标节点。
性质、优点:
- 新增节点时:只会影响新增节点与前一个节点(新增节点逆时针查找的第一个节点)之间的数据。
- 删除节点时:只会影响删除节点与前一个节点(删除节点逆时针查找的第一个节点)之间的数据。
- 虚拟节点:作用在于让环上的节点区间分布粒度变细。用于解决环上的节点数量非常少、可能造成数据分布不平衡的问题。
目的地址哈希调度
LVS 中的
负载均衡分类
负载均衡可以简单分为:
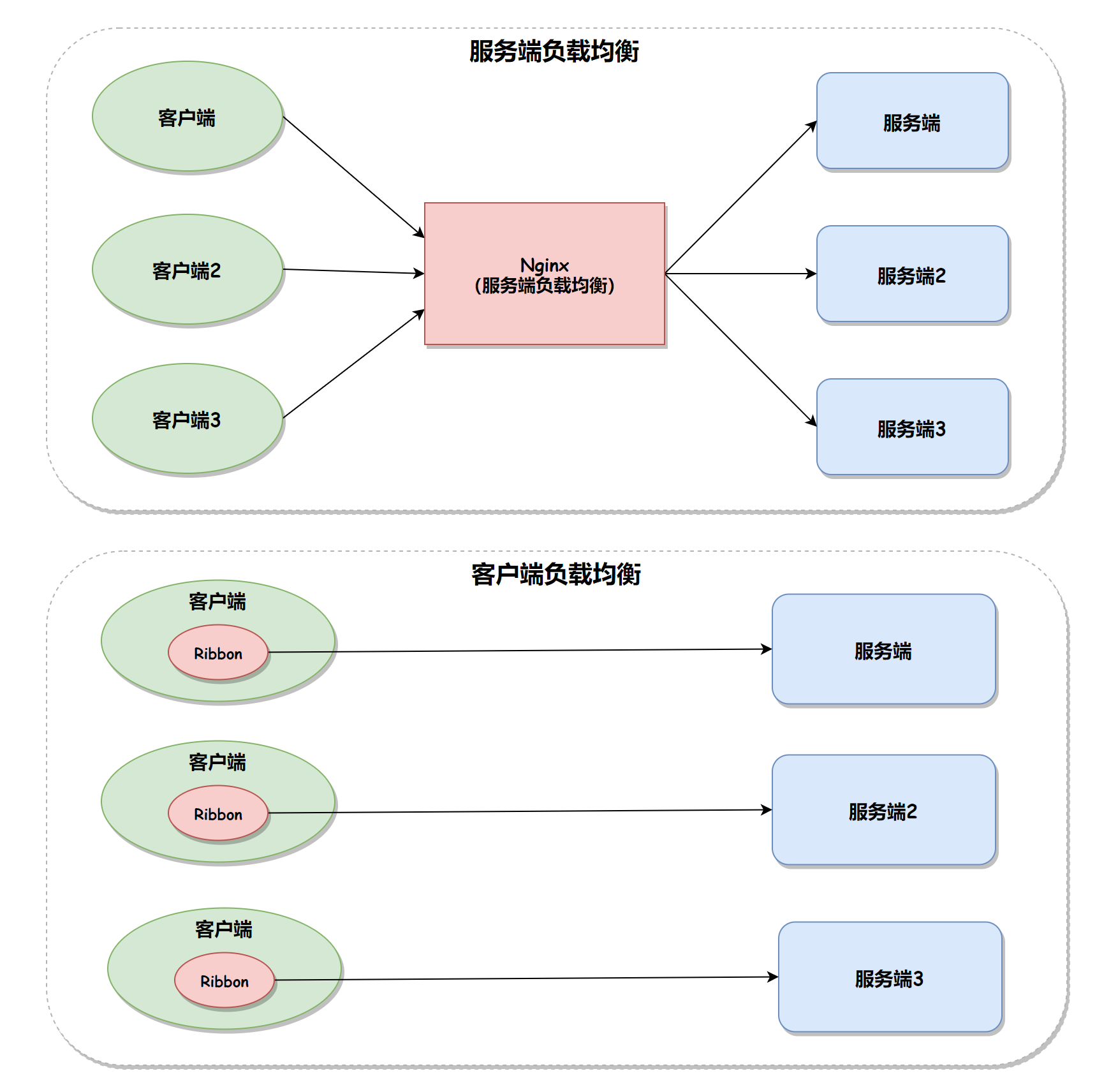
- 客户端负载均衡:主要应用于系统内部的不同的服务之间,可以使用现成的负载均衡组件来实现。
- 客户端会自己维护一份服务器的地址列表,发送请求之前,客户端会根据对应的负载均衡算法来选择具体某一台服务器处理请求。
- 主流的微服务框架都内置了开箱即用的客户端负载均衡实现。 Java 生态最流行的两个负载均衡组件:
Netflix Ribbon:是老牌负载均衡组件,由 Netflix 开发,功能比较全面,支持的负载均衡策略也比较多。(已被弃用)- Spring Cloud Load Balancer:是 Spring 官方为了取代 Ribbon 而推出的,功能相对更简单一些,支持的负载均衡也少一些。(官方,推荐)
- Dubbo:主要是 RPC 框架。
- 服务端负载均衡:
- 硬件负载均衡:通过专门的硬件设备来实现(硬件价格一般很贵)。如 F5 。
- 软件负载均衡:通过软件实现。根据 OSI 七层模型,最常见的是四层负载均衡和七层负载均衡。对于绝大部分业务场景来说,二者的性能差异基本可以忽略不计。
服务端负载均衡器和客户端负载均衡器的区别如下图所示:
多层次负载均衡应用
负载均衡是构建可靠的分布式系统最核心的概念之一。
对于一些大型分布式系统,一般会采用 DNS + 四层负载 +七层负载的方式进行多层次负载均衡。
- 使用 DNS 做为第一级负载均衡,然后在内部使用其它方式做第二级负载均衡;
- 使用 LVS 四层负载均衡(基于 OSPF 路由选择协议)实现多活入口;
- 入口后方为 Nginx 七层负载均衡(反向代理)实现的网关服务。
这些服务与基础架构层组件,例如弹性伸缩、自动化扩容服务等协同工作,实现业务系统高可用、高性能、高并发目标。
四层负载均衡
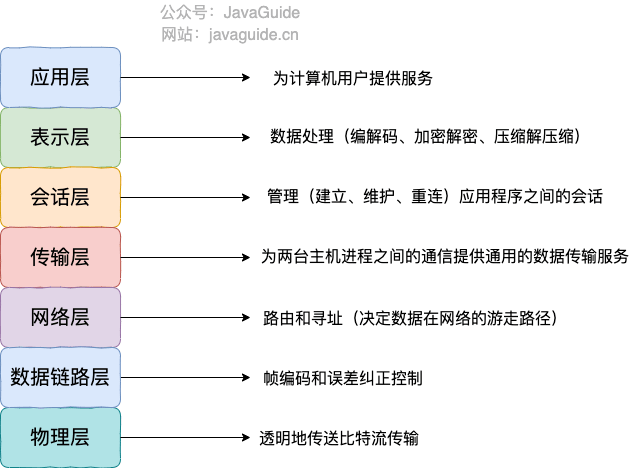
四层负载均衡其实是多种均衡器工作模式的统称,四层的意思是这些工作模式的共同特点是维持同一个 TCP 连接,而不是说它只工作在 OSI 模型的四层。
- 事实上,这些模式主要工作在第二层(数据链路层,改写 MAC 地址)和第三层(网络层,改写 IP 地址),
- 而第四层(传输层,改写 TCP/UDP 等协议的内容端口号)单纯只处理数据,做 NAT 之类的功能,所以无法做到负载均衡的转发。
- 因为 OSI 模型的下三层是媒体层(Media Layer),上四层是主机层(Host Layer),既然流量已经到了目标主机了,也谈不上什么流量转发,最多只能做代理。
- 但出于习惯,现在大多数资料都把它们统称为四层负载均衡。
四层负载均衡器最典型的软件实现是 LVS。这是目前大型网站使用最广的负载均衡转发方式。
典型情况下,四层负载均衡器只工作在传输层 TCP/UDP connection/session 中,不论采用何种的负载均衡算法,都是力求同一 session 的字节永远落到同一后端。
(二层)数据链路层
数据链路层:负责修改请求数据帧中的 MAC 目标地址,让原本发送给负载均衡器的数据帧,被二层交换机转发至服务器集群中对应的真实服务器。
具体原理:
- 转发:
- 由于链路层只修改了 MAC 地址,所以在 IP 层看来数据没有任何变化,继而被正常接收。
- (IP 数据包中包含了源(客户端)和目的地(负载均衡器)IP 地址),通过配置真实服务器的虚拟 IP 地址和负载均衡服务器的 IP 地址一致,从而不需要修改 IP 地址就可以进行转发。
- 响应:也正因为 IP 地址一样,所以真实服务器的响应不需要原路返回负载均衡服务器,可以直接转发给客户端。
整个请求、转发、响应的链路形成一个“三角关系”,所以这种模式也被形象的称为“三角传输模式”(Direct Server Return,DSR),也称为“单臂模式”(Single Legged Model)、直接路由,如图所示。
- 优点:对于提供下载和视频服务的网站来说,避免了大量的网络传输数据经过负载均衡服务器、而导致负载均衡服务器成为瓶颈。

(三层)网络层
网络层:通过操作系统内核进程获取网络数据包,修改 IP 数据包的目的 IP 地址来实现数据转发。
- 源服务器返回的响应也需要经过负载均衡服务器,通常是让负载均衡服务器同时作为集群的网关服务器(传输层)来实现。
优点:在内核进程中进行处理,性能比较高。
缺点:和反向代理一样,所有的请求和响应都经过负载均衡服务器,可能成为性能瓶颈。
(四层)传输层 TCP
传输层:改写 TCP、UDP 等协议的内容端口号,单纯只处理数据。
- 负载均衡器在这一层能够看到数据包里的源端口地址以及目的端口地址,会基于这些信息(通过一定的负载均衡算法)将数据包转发到后端真实服务器。
- 也就是说,四层负载均衡的核心就是 IP+端口层面的负载均衡,不涉及具体的报文内容。
LVS 负载均衡服务器
LVS 负载均衡服务器
LVS(Linux Virtual Server,Linux 虚拟服务器):LVS不直接处理请求,而是将客户端请求转发、分发到多个后端真正的服务器上。工作在四层网络层。
- 是一个虚拟的服务器集群系统,可以在UNIX/LINUX平台下实现负载均衡集群功能。
- 通过实现负载均衡,LVS能够提供稳定、可靠、高效的服务,满足大规模系统的需求。
- LVS支持多种调度算法,如轮询、最少连接、源地址哈希等,用于决定请求的转发方式。
- LVS是四层,传输层 tcp/udp。LVS 负责四层协议转发,无法按 HTTP 协议中的请求路径做负载均衡,所以还需要 Nginx。
- 还提供了高可用性的机制,包括热备份和故障自动切换。
- LVS具有灵活的配置和扩展性,适用于各种网络环境和应用场景。
业务实战:对于千万级流量的秒杀业务,一台LVS扛不住流量洪峰,通常需要 10 台左右,其上面用DDNS(Dynamic DNS)做域名解析负载均衡。搭配高性能网卡,单台LVS能够提供百万以上并发能力。
参考:负载均衡服务-LVS
工作原理
LVS 集群负载均衡器接受服务的所有入站客户端计算机请求,并根据调度算法决定哪个集群节点应该处理回复请求。
负载均衡器(简称 LB)有时也被称为 LVS Director(简称Director)。
三种工作模式
以 IP 协议为例,一个 IP 数据包由头部(Header)和载荷(Payload)组成,Header 内部包含版本、源地址、目的地地址等信息。
从网络数据包转发的角度去解释 LVS 中 DR、NAT、Tunnel 模式是如何工作的。
- DR 模式:其实是一种链路层负载均衡。直接转发。
- Tunnel、NAT 模式都属于网络层负载均衡,只不过因为对 IP 数据包的不同形式修改而分成两种。
- Tunnel 模式:保持源数据包不变,把源数据包封装在新建的 IP 数据包内,再通过三层交换机发送出去。真实服务器收到包之后,有一个对应拆包的机制,解析出(Payload 内部的)IP 数据包再进行正常处理。其实就是一种隧道技术。
- NAT 模式(
Network Address Translation):直接改变 IP 数据包的(Header 内的)目的地址(改为真实服务器的地址),修改之后原本用户发送给负载均衡器的数据包会被三层交换机转发至真实服务器的网卡上。
十种调度算法
当Director调度器收到来自客户端计算机访问它的 VIP上的集群服务的入站请求时,Director调度器必须决定哪个集群节点应该处理请求。
Director调度器可用于做出该决定的调度方法分成两个基本类别:
- 固定调度方法:rr 轮询,wrr 权重轮循,dh 目的地址哈希调度,sh 源地址哈希调度。
- 动态调度算法:wlc 加权最小连接数调度,lc 最小连接数调度,lblc,lblcr,SED,NQ。
七层负载均衡
七层负载均衡工作在 OSI 模型的第七层,即应用层,这一层的主要协议是 HTTP 。
- 这一层的负载均衡比四层路由网络请求的方式更加复杂,它会读取报文的数据部分(比如说 HTTP 部分的报文),然后根据读取到的数据内容(如 URL、Cookie)做出负载均衡决策。
- 也就是说,七层负载均衡器的核心是报文内容(如 URL、Cookie)层面的负载均衡 。
- 优缺点:七层负载均衡比四层会消耗更多的性能,不过,也相对更加灵活,能够更加智能地路由网络请求,比如说可以根据请求的内容进行优化,如缓存、压缩、加密。
执行第七层负载均衡的设备通常被称为反向代理服务器,最常用的就是Nginx。
- 配合 Lua,如 OpenResty,能扩展实现功能丰富且性能较高的网关方案。
NginX 反向代理服务器
HTTP 重定向
HTTP 状态码在七层应用层。
HTTP 重定向负载均衡服务器:(使用某种负载均衡算法)计算得到服务器的 IP 地址之后,将该地址写入 HTTP 重定向报文中,状态码设置为 302。客户端收到重定向报文之后,需要重新向服务器发起请求。
缺点比较明显,实际场景中很少使用:
- 需要两次请求,因此访问延迟比较高;
- HTTP 负载均衡器处理能力有限,会限制集群的规模。
DNS 域名解析负载均衡
大型网站基本使用了 DNS 做为第一级负载均衡手段,然后在内部使用其它方式做第二级负载均衡。
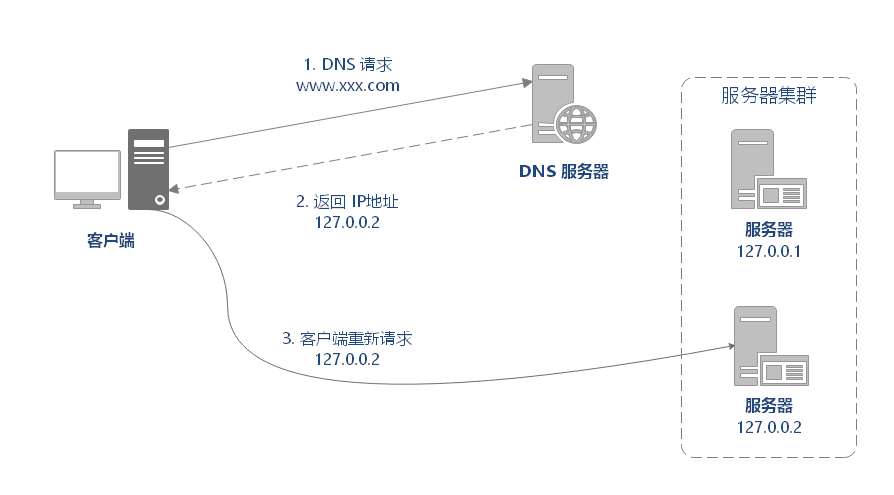
原理:在 DNS 负载均衡服务器中为同一个域名配置多个 IP 地址,这些 IP 地址对应不同的服务器。
- DNS 域名解析的结果、获得的 IP 地址为内部的负载均衡服务器的 IP 地址。
- 负载均衡服务器根据设定的分配算法和规则(如根据每台机器的负载量,离用户地理位置的距离等),选择一台后端的(真实) Web 服务器的 IP 地址并返回。
如,DDNS(Dynamic DNS)。
当用户请求域名时,DNS 服务器采用轮询算法返回 IP 地址,这样就实现了轮询版负载均衡。
- 优点:
- 零成本:只是在DNS服务器上绑定几个A记录,域名注册商一般都免费提供解析服务;
- 部署简单:就是在网络拓扑进行设备扩增,然后在DNS服务器上添加记录。
- DNS 能够根据地理位置进行域名解析,返回离用户最近的服务器 IP 地址。
- 缺点:
- 可靠性低:假设一个域名DNS轮询多台服务器,如果其中的一台服务器发生故障,那么所有的访问该服务器的请求将不会有所回应。由于 DNS 具有多级结构,每一级的域名记录都可能被缓存,当下线一台服务器需要修改 DNS 记录时,需要过很长一段时间才能生效。
- 负载分配不均匀(有,但不会有那么大的影响):采用的是简单的轮询算法,不能区分服务器的差异,不能反映服务器的当前运行状态,不能做到为性能较好的服务器多分配请求,甚至会出现客户请求集中在某一台服务器上的情况。
客户端负载均衡
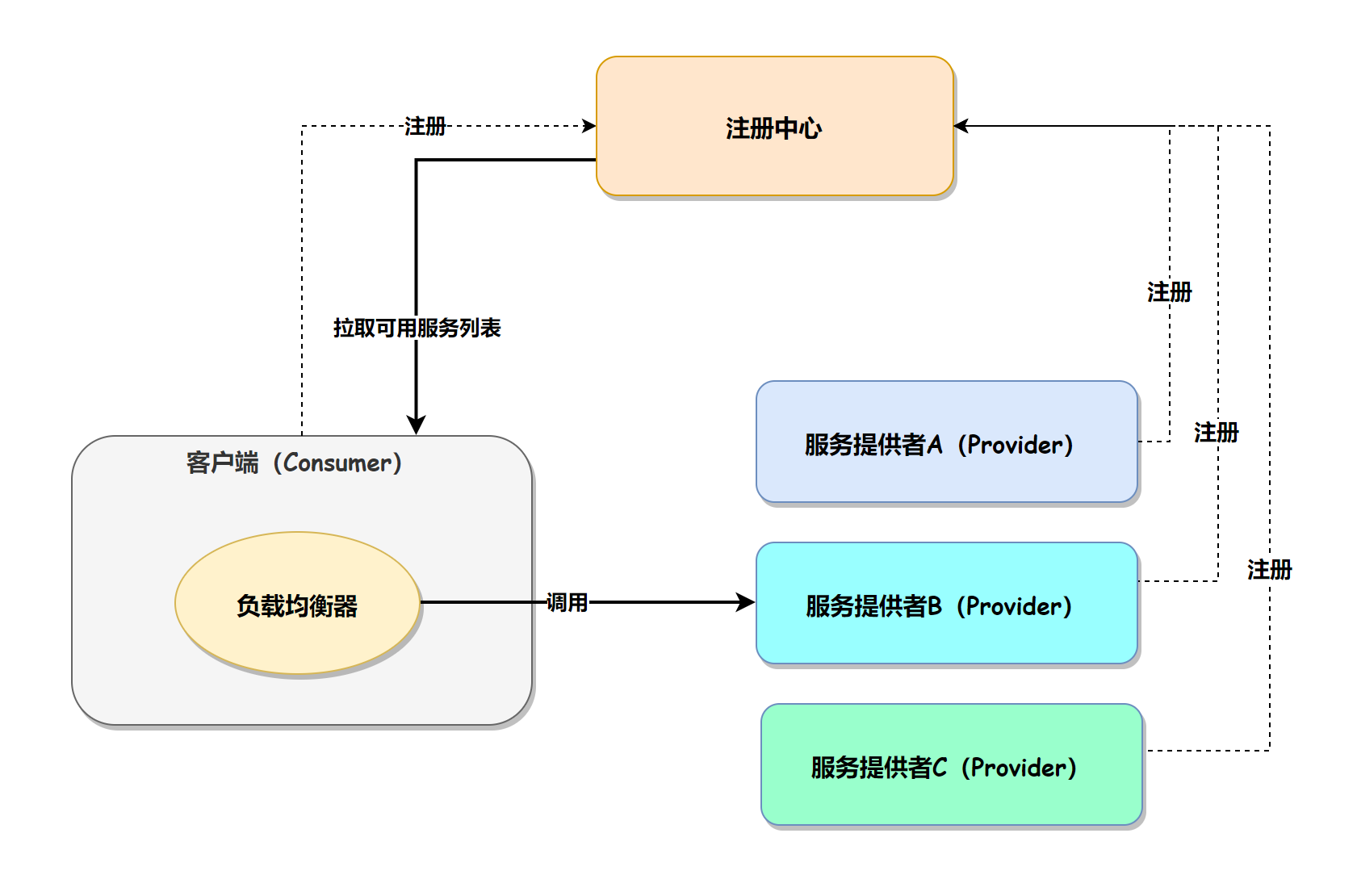
客户端负载均衡器的实现原理是:
- 通过注册中心(如 Nacos)将可用的服务列表拉取到本地(客户端),
- 再通过客户端(Consumer)负载均衡器(设置的负载均衡策略)获取到某个服务器(服务提供者 Provider)的具体 ip 和端口,
- 然后再通过 Http 框架请求服务并得到结果。
其执行流程如下图所示:
Spring Cloud提供了 Ribbon 和 Feign 作为客户端的负载均衡。
- Spring Cloud Ribbon 为客户端提供跨服务实例负载平衡的能力。
- 在 Spring Cloud 下,使用 Ribbon 直接注入一个 RestTemplate 对象即可,此RestTemplate已做好负载均衡的配置;使用 @LoadBalanced 注解赋予RestTemplate负载均衡的能力。
- 可以看出使用Ribbon的负载均衡功能非常简单,和直接使用RestTemplate没什么两样,只需给RestTemplate添加一个@LoadBalanced即可。
- 而使用Feign只需定义个注解,有
@FeignClient注解的接口,然后使用@RequestMapping注解在方法上映射远程的REST服务,此方法也是做好了负载均衡配置。