摘要:是一个基于发布订阅模式的消息队列中间件。由 Producer, Consumer, Broker 和 Partition 几个组成。
目录
[TOC]
Kafka
Kafka:是一个基于发布订阅模式的消息队列中间件。
Kafka 有三个关键功能:
- 发布和订阅消息流:类似于消息队列。
- 容错的持久化方式存储消息流: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
- 流式处理平台: 在消息发布时进行处理,Kafka 提供了一个完整的流式处理类库。
主要有两大应用场景:
- 消息队列:
- 数据处理:
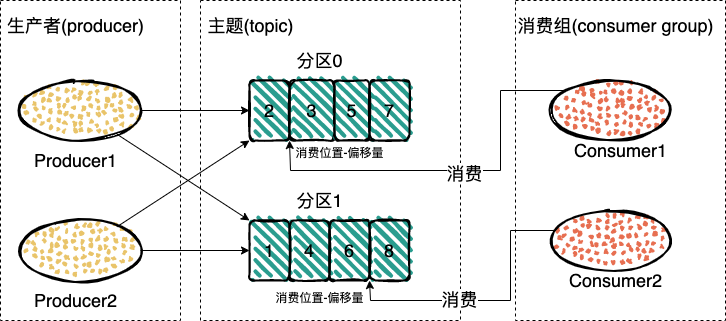
消息模型
默认端口 9090,producer、consumer 9092?
与 RocketMQ 的消息模型基本一样,唯一区别是没有队列这个概念,对应的是 Partition(分区)。
还引入了 broker、Consumer Group。
技术架构
由 Producer、Consumer、Broker 和 Partition 组成。
Producer
Producer:依据负载均衡设置,将消息发送到 Topic 的特定 Partition 下。
Broker
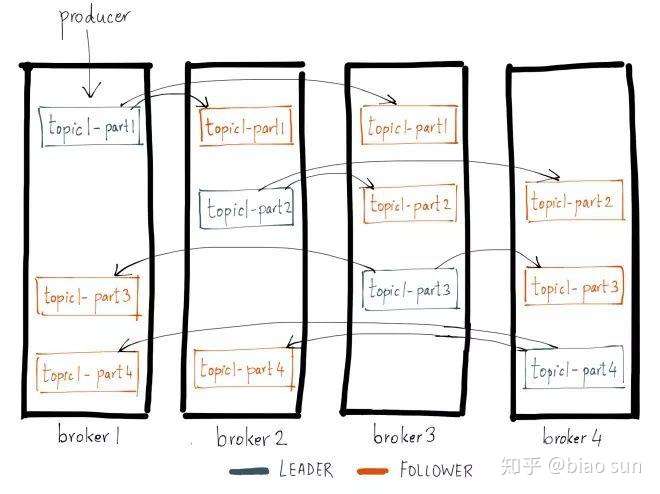
Broker :一个 Kafka 集群由多个 Broker 组成,每个broker都是一个节点,存放着不同 Topic 的(不同) Partition。
功能:
- 接收生产者的信息,为消息设置偏移量,并且保存的磁盘中。
- broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
- 同时 broker 也会对生产者和消费者进行消息的确认,没有收到会重新发送这条消息。
Topic
主题:Kafka 里面的每一个消息都属于一个主题,每一个topic可以划分为多个partition,而每个partition放一部分数据,分别存在于不同的 broker 上。
- 也就是说,一个
topic的数据,是分散放在多个机器上的,每个机器就放一部分数据。
Partition
Partition:为了提高消费的性能而引入,实际上可对应成消息队列中的队列。
- 同一 Topic 下的这些 Partition 均匀分布在(横跨)多个不同的 Broker 上,使用主从复制模式同步,以保证高可用。
- 每一个 Partition 内消息是有序的,即分区顺序性。(引出如何保证消息有序性)。
- 由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
Consumer Group
消费者通过偏移量来确认读过的数据,是个不断累加的数据,每次成功消费一个数据这个偏移量就加一。
- 在给定的分区中,每个消息的偏移量都是唯一的。
- 消费者会把每个分区读取的消息偏移量保存在 Zookeeper 或 Kafka 上,如果消费者关闭或重启,它的读取状态不会丢失。
Consumer 之间组成了 Consumer Group:通过多消费者,这样消费的性能就提高了。
- 同一个 Topic 可以被多个 Consumer Group 消费,互相之间不会有影响。
- 不过同组内的消费者是竞争关系,同组内一个消息只能被同组内的一个消费者消费。
- (Kafka 强制要求)每个 Partition 只能有一个 Consumer 消费,并且 Consumer 采取拉模式(拉模型),消费完一批消息之后再拉取一批。
高性能
Kafka 高性能依赖于非常多的手段:
- 零拷贝(重点):在 Linux 上 Kafka 使用了两种手段,
mmap(内存映射)和sendfile,前者用于解决Producer写入数据,后者用于Consumer读取数据; - 顺序写:Kafka 的数据,可以看做是 AOF (
append only file),只允许追加数据,而不允许修改已有的数据。消息以追加的方式写入Partition,然后以先入先出的顺序读取。- AOF 在数据库(如 MySQL,Redis)上也很常见,这也是为什么一般说 Kafka 用机械硬盘就可以了。 和 SSD Kafka 在性能上差距不大;
- Page Cache(系统缓存):Kafka 允许落盘的时候,是写到 Page Cache 时就返回,还是一定要刷新到磁盘(主要就是mmap 之后要不要强制刷新磁盘)。
- 类似的机制在 MySQL, Redis上也是常见,(简要评价一下两种方式的区别)
- 如果写到 Page Cache 就返回,那么会存在数据丢失的可能。
- 批量操作:包括 Producer 批量发送、Broker 批量落盘。批量能够放大顺序写的优势,比如说 Producer 还没攒够一批数据发送就宕机,就会导致数据丢失;
- 批量发送和数据压缩,在处理大数据的中间件中比较常见。比如说分布式追踪系统 CAT 和 skywalking 都有类似的技术。代价就是存在数据丢失的风险;
- 数据压缩:能减少数据传输量,提高效率;
- 但是会消耗更多 CPU。不过在 IO 密集型的应用里面,这不会有什么问题;
- 日志分段存储:Kafka 将日志分成不同的段,只有最新的段可以写,别的段都只能读。
- 同时为每一个段保存了偏移量索引文件和时间戳索引文件,采用二分法查找数据,效率极高。
- 同时 Kafka 会确保索引文件能够全部装入内存,以避免读取索引引发磁盘 IO。
零拷贝
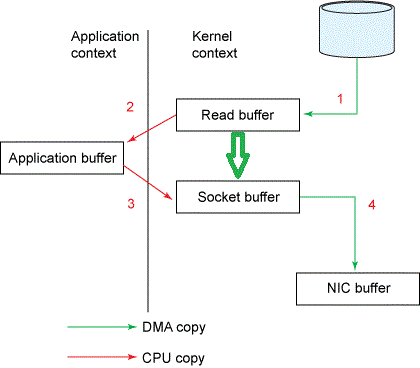
一般的数据从磁盘到网络(或者从网络到磁盘),都需要经过四次拷贝。比如说磁盘到网络,要经过:
- DMA 拷贝:磁盘到内核(读)缓冲区
- CPU 拷贝:内核缓冲区到应用缓冲区
- CPU 拷贝:应用缓冲区到内核(Socket)缓冲区
- DMA 拷贝:内核缓冲区到网络(NIC)缓冲
零拷贝:并不是说完全没有拷贝,而是指没有 CPU 参与(红色的第二和第三步)的拷贝,DMA 拷贝还在。
Kafka 利用了两项零拷贝技术:
mmap:用于解决网络数据落盘的,Kafka 直接利用内存映射,完成了“写入操作”,对于 Kafka 来说,完成了网络缓冲区到磁盘缓冲区的“写入”,之后强制调用flush或者等操作系统(有参数控制)。- Java 提供了
FileChannel和MappedByteBuffer两项技术来实现 mmap。
- Java 提供了
sendfile:主要解决磁盘到网络的数据传输。操作系统读取磁盘数据到内存缓冲,直接丢过去socket buffer,而后发送出去。很多中间件,例如Nignx,tomcat都采用了类似的技术。
为什么顺序写那么快?
AOF
Page Cache(系统缓存)
高可用
- 分区分布
- 主从复制:复制多副本机制
- ISR 同步副本集
分区分布
分区数量过多
注意这里说的分区过多,一般都是指 Topic 中分区很多,而不是指一个主分区有一千个从分区。
后者,要从 ISR 的角度去分析。不过基本上不会面这个问题,面到了就怼回去,谁家的主分区会有一千个从分区。
能不能通过增加分区数量来提高 Kafka 性能?
- 注意,这个是可以的,但是要注意把握度,就是不能无限增加。
Topic 分区过多会引起什么问题?
- 分区数量是不是越多越好?显然不是;
- Topic 过多会引起什么问题?其实差不多是同一个问题,Topic 多意味着分区多,而且通常伴随的是每个 Topic 的数据量都不大;
要从 Producer、Consumer 和 Broker 三者考虑:
- 对于
Producer来说:采用的是批量发送的机制,那么分区数量多的话,就需要消耗大量的内存来维护这些缓存的消息。同时,也增大了数据丢失的风险。 - 对于
Consumer来说:分区数量多意味着要么部署非常多的实例,要么开启非常多的线程,无论是哪一种方案,都是开销巨大。 - 对于
Broker来说:分区特别多而对应的 Broker 数量又不足的话,那么意味着一个 Broker 上分布着大量的分区,那么一次宕机就会引起 Kafka 延时猛增。- 同时,每一个分区都要求 Broker 开启三个句柄,那么会引起 Broker 上的文件句柄被急速消耗,可能导致程序崩溃。
- 还要考虑到,Kafka 虽然采用了顺序写,但是这是指在一个分区内部顺序写,在多个分区之间,是无法做到顺序写的。
解决方法
- 增加 Broker,确保 Broker 上不会存在很多的分区。这可以避免 Broker 上文件句柄数量过多,顺序写退化为随机写,以及宕机影响范围太大的问题。
- 其次可以考虑拆分 Topic 并且部署到不同的集群。(注意,Topic 如果拆了但是没有增加 Broker,也没有部署额外的 Kafka 集群,那么其实还是没啥用)
- 当然,如果分区的写入负载其实并不大,那么可以考虑削减分区的。(kafka本身不支持削减分区)
不支持减少分区
Kafka 增加分区是可以的,但是减少分区是不能的。
原因:
- 实现减少分区的核心难点在于,难以处理分区上的数据。
- 比如,减少的这个分区上的数据怎么处理?
- 大多数情况下,不能直接丢掉,那么只能考虑重新分配给其它的分区。
- 于是就涉及到,如何分配,对应的消费者怎么处理?以及对其余分区的影响。
- 总体来说,减少分区的复杂度,远比增加分区的复杂度大,但是收益是小的。
- 一方面,有别的手段来解决类似的问题,
- 另一方面,大多数的场景,都是增加分区,而不是减少分区。
假如要实现类似的功能,可以考虑两种方案:
- 创建一个完全一样的 Topic,然后分区数量少一点,等老的 Topic 消费完就直接下线,只留下这个新的 Topic;
- 考虑在写入分区时,不再写入特定的分区,可以通过业务来控制,也可以通过负载均衡机制来控制;
- 缺点是:这个没用的分区会长期存在,并没有在事实上删除它。
确定合适的分区、消费者数量
如何确定消费者数量?
要注意,消费者最多最多就是和分区数量一样,其它就是压测了。
答:使用 Kafka 提供的压测工具来测试。
- 一般来说,我们对于某个特定的 Topic,其消息大小是能够从业务上推断出来的,也就是我们不存在说一个 Topic,某些消息特别长,某些消息特别短。大部分的消息长度都在相差不多的范围内。
- 因此我们可以控制写入一个分区的 TPS,观察同步延时和消息是否积压(消费端的消费数据,例如99线等也可以)。
- 分区数量会影响两端,因此要同时考虑 Producer 的效率和 Consumer 的效率。
复制多副本机制
每个
partition放一部分数据,如果对应的broker挂了,那这部分数据是不是就丢失了?
Kafka 0.8 之后,提供了复制多副本机制来保证高可用,即:
- 每个
partition的数据都会同步到其它机器上,形成多个副本。 - 所有的副本会选举一个
leader出来,让leader去跟生产和消费者打交道,其他副本都是follower。 - 写数据时,
leader负责把数据同步给所有的follower,读消息时,直接读leader上的数据即可。- 发送的消息会被发送到
leader,然后follower副本才能从leader中拉取消息进行同步。
- 发送的消息会被发送到
如何保证高可用的?
- 假设某个
broker宕机,这个broker上的partition在其他机器上都有副本。 - 如果挂的是
leader的broker呢?其他follower会重新选一个leader出来。
从 Partition 不提供读服务
原因:
- 首先是 Kafka 自身的限制:即 Kafka 强制要求一个 Partition 只能有一个 Consumer,因此 Consumer 天然只需要消费主 Partition 就可以。
- 假如说 Kafka 放开这种限制,允许读从 Partition 的数据。比如说有多个 Consumer,分别从主 Partition 和从 Partition 上读取数据,那么会出现一个问题:即偏移量如何同步的问题。而这是分布式一致性的问题,难以解决。
- 消费者消费特点:而从另外一个角度来说,Kafka 的读取压力是远小于 MySQL 的,毕竟一个 Topic,是不会有特别多的消费者的。并且 Kafka 也不需要支持复杂查询,所以完全没必要读取从 Partition 的数据。
ISR 同步副本集
主从复制
基本机制
ISR(In-Sync Replicas )同步副本集:是分区同步的概念,是一种主从同步机制。
-
ISR 动态维护了一个和 leader 副本保持同步的所有副本的集合,ISR 中的副本全部都和 leader 的数据保持同步。
-
Kafka 为每个主分区维护了一个 ISR,处于 ISR 的分区意味着与主分区保持了同步(所以主分区也在 ISR 里面)。
当 Producer 写入消息的时候,需要等 ISR 里面分区的确认,当 ISR 确认之后,就被认为消息已经提交成功了。
- ISR 里面的分区会定时从主分区里面拉取数据。如果长时间未拉取,或者数据落后太多,分区会被移出 ISR。
- ISR 里面分区已经同步的偏移量被称为 LEO(
Log End Offset),最小的 LEO 称为 HW(高水位,high water),也就是消费者可以消费的最新消息。 - 如果 ISR 里面的分区已同步消息是木桶的木板的话,高水位就取决于最短的那个木板,也就是同步最落后的。
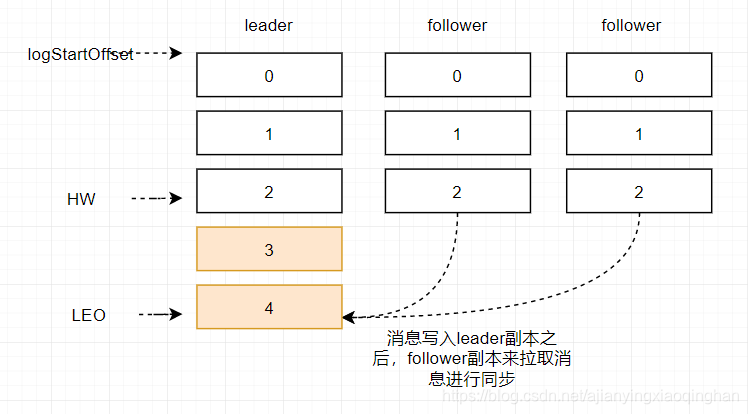
什么时候分区会被移出 ISR?
Kafka 如何维护 ISR 的。
Kafka GC 时间过长会导致什么问题?可能导致分区被踢出去 ISR。
答案:通过两个参数控制维护 ISR。当分区触发两个条件中的任何一个时,都会被移除出 ISR。
- 消息落后太多:由参数
‘replica.lag.max.messages控制。0.9.0后被移除 - 分区长时间没有发起
fetch拉取请求:由参数replica.lag.time.max.ms控制。
刷亮点:
- 这些因素怎么影响的:基本上,除非是新的 Broker,否则几乎都是由网络、磁盘IO和GC引起的。大多数情况下,是负载过高导致的。
- 过大过小的影响:这两个参数,过小会导致 ISR 频繁变化,过大会导致可靠性降低,存在数据丢失的风险。
补充: 为什么kafka要将replica.lag.max.messages删除?
- 因为这个参数本身很难给出一个合适的值。
- 以默认的值4000为例,对于消息流入速度很低的主题(比如TPS为10),这个参数就没什么用;
- 对于消息流入速度很高的主题(比如TPS为2000),这个取值又会引入ISR的频繁变动(ISR 需要在Zookeeper中维护)。
- 所以从0.9x版本开始,Kafka就彻底移除了这一个参数。
可靠性
- Kafka 是如何保证可靠性的?
- 如何提高 Kafka 的可靠性
- 如何提高 Kafka 吞吐量?可靠性和吞吐量在这里就是互斥的,调整参数只能提高一个,降低另外一个。
ACK 机制
在 Producer 里面可以控制 ACK 机制写入消息。Producer 可以配置成三种:
- Producer 发出去就算成功;
- Producer 发出去,主分区写入本地磁盘就算成功;
- Producer 发出去,ISR 所有的分区都写入磁盘,就算成功;
其性能依次下降,但是可靠性依次上升。
ISR 中分区不能少于三个
当主分区挂掉的时候,会从 ISR 里面选举一个新的主分区出来。
因为 ISR 里面包含了主分区,也就是说,如果整个 ISR 只有主分区,那么全部写入就退化为主分区写入。
- 所以在可靠性要求非常高的情况下,要求 ISR 中分区不能少于三个。通过在 Broker 中配置
min.insync.replicas参数。
避免 Broker 宕机
除了 ISR 以外,还要强调一下
Partition 是分布在不同 Broker 上,以避免 Broker 宕机导致 Topic 不可用。
其它中间件主从同步机制
ISR 的同步机制和其它中间件机制也是类似的,在涉及主从同步时都要在性能和可靠性之间做取舍。通常的选项都是:
- 主写入就认为成功
- 主写入 + 至少一个从写入就认为成功;
- 主写入 + 大部分从库写入就认为成功(一般“大部分”是可以配置的,从这个意义上来说,2和3可以合并为一点);
- 主写入 + 所有从库写入就认为成功;
而“写入”也会有不同语义:
- 中间件写到日志缓存就认为写入了;
- 中间件写入到系统缓存(
page cache)就认为写入了; - 中间件强制刷新到磁盘(发起了 fsync)就认为写入了;
都是性能到可靠性的取舍。
如何保证消息有序性?
答:Kafka 要做到消息有序,只需要将消息都投递到同一个分区里面。
- 分区内部有序的特点:因为 Kafka 的设计确保了一个分区内部的消息是有序的。但是分区之间是没有顺序的。
- 这并不意味着只能使用一个分区,而是可以考虑在发消息时主动指定分区,确保业务上要求顺序的消息都被投递到同一个分区中。
- 例如按照用户 ID 来选择分区,确保用户相关的某些消息都在同一个分区内部。
- (点出缺点)类似的方案都要注意分区负载,例如热点用户产生了大量的消息,都被积压在该分区。
全局有序消息
比如Kafka的全局有序消息:生产者发消息时,1个Topic只能对应一个Partition(分区)、一个 Consumer,内部单线程消费。发送消息时指定 key/Partition。
Kafka 的负载均衡策略
- 如何选取 Hash Key
- 你们是如何设置 Producer 推送消息到哪个 Partition 的?
答案:一般来说有两种:
- 一种是轮询:即 Producer 轮流挑选不同的 Partition;
- 另外一种是 Hash 取余:这要求我们提供 Key。这取决于 Key 是否为 Null。
- Key 的选取,大原则上是采用业务特征 ID,或者业务特征的某些字段拼接而成。
- 对 Partition 负载的影响:比如说,可以考虑按照用 Order ID 作为 Key,这意味某个订单的消息肯定落在特定的某个 Partition 上,这就保证了针对该订单的消息是有序的。
- 风险、缺点:Partition 负载均衡与消费者负载均衡不匹配:
- 如果 Key 设置不当,可能会导致某些 Partition 承载了大多数的流量。比如说按照商家 ID 来作为 Key,那么可能某些热点商家、大卖家,其消息就集中在某个 Partition 上,导致负载不均衡。
- 消息的确分布均匀了,但是处理不同的消息可能有快有慢。在极端情况下,可能处理慢的消息都在特定的 Partition 上,因此导致某个消费者负载奇高,而其余的消费者却没有什么负载。
- Key 的选取,大原则上是采用业务特征 ID,或者业务特征的某些字段拼接而成。
- 无论是轮询,还是 Hash,都无法解决一个问题:都只考虑 Partition 的负载,而没有考虑 Consumer 的负载。(进一步凸显自己对负载均衡的理解)
- 例如,可以用 Hash 策略均匀分布了消息,但是可能某些消息消费得慢,有些消息消费得快。
- 假如说非常不幸,消费得慢的消息都落在某个 Partition,那么该 Partition 的消费者和别的消费者比起来,消费起来就很慢,带来很大的延迟,甚至出现消息堆积。
- 解决这个问题,可以用负载均衡算法中的最小连接(加权最小连接)、最少活跃法、最快响应时间法。
Rebalance
Rebalance 本质就是给消费组的消费者分配任务的过程。
发生时机、原因
- Topic 或者分区的数量变化(例如,扩容、增加新的分区);
- 消费者数量变化(加入或者退出)。又可以细分为两个:
- 消费超时(
max.poll.interval.ms), - 心跳超时(
session.timeout.ms)
- 消费超时(
如何避免
根据发生时机、原因分析:
- 首先,Topic 或者分区变化,引起的 rebalance 是无法避免的,因为一般都是因为业务变化引起的。比如说,随着流量增加,要增加分区。
- 能够避免的就是防止消费者数量变化,引起的 rebalance。
- 消费超时:可以增大
max.poll.interval.ms参数,避免被协调者踢掉。或者优化消费逻辑,使得消费者能够快速消费,拉取下一批消息。 - 心跳超时:可以通过增大
session.timeout.ms来缓解。 - 这两个参数增大的弊端:都可能导致,消费者真的出了问题,但是协调者却迟迟没有感知到的问题。
- 消费超时:可以增大
过程
实际上,不同原因引起的 rebalance 过程是有一些差异的,不过这些差异不涉及根本,所以没必要纠结。
更加简单的记忆方式是:挑选 leader -> leader 出方案 -> 同步方案。
- 就很像一堆同事说我来搞负责解决这个问题,然后老板挑了一个卷王,说你出个方案,老板看了方案很满意,交代其它同事说按照这个方案执行。
答:以新的消费者加入(引起的 rebalance)为例,这个步骤可以分成以下几步:
- 挑选 leader:
- 新的消费者向协调者上报自己的订阅信息;
- 协调者强制别的消费者发起一轮 rebalance,上报自己的订阅信息;
- 协调者从消费者中挑选一个 leader,注意这里是挑选了消费者中的 leader;
- leader 出方案:
- 协调者将订阅信息发给 leader,让 leader 来制作分配方案;
- leader 上报自己的方案;
- 同步方案:协调者同步方案给别的消费者。
有啥影响
结合 rebalance 的过程,可以看到,rebalance 对消费者的影响是最大的。因为在 rebalance 的过程中,都不能消费。
- 重复消费:如果在消费者已经消费了,但是还没提交,这个时候发生了 rebalance,那么别的消费者可能会再一次消费;
- 影响性能:rebalance 的过程,一般是在几十毫秒到上百毫秒。这个过程会导致集群处于一种不稳定状态中,影响消费者的吞吐量;
拉模型、推模型
为什么 Kafka 在消费者端采用了拉(PULL)模型?
在 MQ 这种场景下的优缺点。加分点在于明确指出什么 MQ 使用了什么模型。
答:采用拉模型的核心原因在于,消费者的消费速率不同。
- 在拉模型之下:消费者自己消费完就再去拉去一批,那么这种速率是由消费者自己控制的,所需要的控制信息也是由消费者自己保存的。
- 而采用推模型:就意味着中间件要和消费者就速率问题进行协商,否则容易导致要么推送过快,要么推送过慢的问题。
- 好处是:避免竞争。例如在多个消费者拉同一主题的消息的时候,就需要保证,不同消费者不会引起并发问题。
- 而 Kafka 不会有类似的问题,因为 Kafka 限制了一个 Partition 只能有一个消费者,所以拉模型反而更加合适。
Kafka 能不能重复消费?
分析:这个问题,其实不是指我们之前提到的,消费者如何避免重复消费中的那种因为超时引起的重复消费。
面试官想问的是,能不能主动重复消费(历史上的消息)。比如说,程序有BUG,消费时出错了。等修复完 BUG 之后,打算重新消费一遍,有没有办法做到。
答:能。Kafka 的分区用 offset 来记录消费者消费到哪里了。因此可以考虑指定 offset 来消费,比如指定一个很久之前的 offset。
- 一些场景之下,会更加倾向于指定时间节点,那么可以先根据时间戳找到 offset,然后再从 offset 消费。
- 消息保存时间,因为超过消息保存时间,就真找不着了。
- 不过要注意,有些时候,消息可能已经被归档了,就确实没法重复消费了。
Zookeeper 在 Kafka 中的作用
- Broker 注册
- Topic 注册
- 负载均衡
- 维护分区被移出 ISR 的参数