摘要:Java 高级之集合框架/容器类,包括 List、Queue、Set、Map。
目录
[TOC]
集合框架(容器类)
所有集合类都位于 java.util 包下,用于表示和操作对象集合,包含大量集合接口及其实现类和操作算法。
集合类 VS 数组:
- 数组元素既可是基本类型的值,也可是对象的引用;
- 而集合只能保存对象的引用,对象本身存放在堆或方法区。基本数据类型在栈上分配内存,随时被回收,通过自动装箱可把基本类型转为包装类,存放在集合中。
Collection 接口及分类
各种实现类的底层实现原理、实现类的优缺点。
-
重写
toString()来打印内容,否则默认打印地址。 -
singleton() 方法:
1 | |
集合容器继承关系图
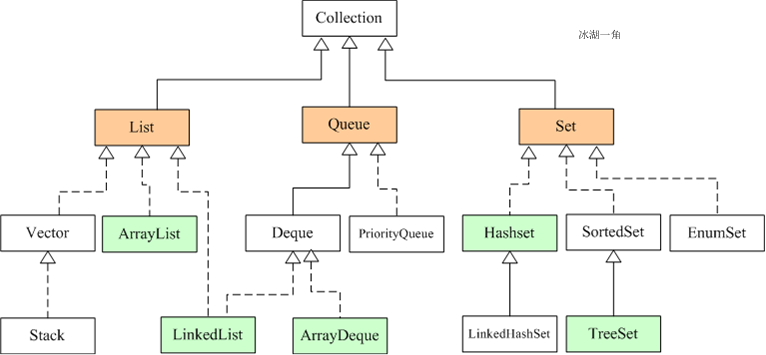
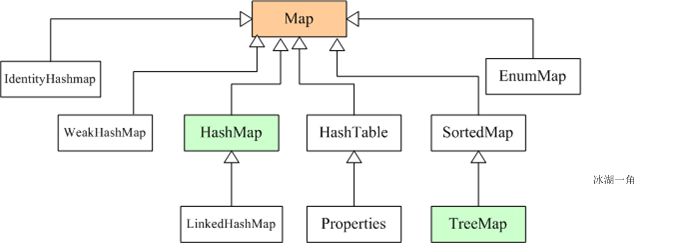
List、Queue、Set、Map 接口
List、Queue、Set 接口继承自 Collection 接口:
1 | |
List:有序、可重复,允许多个null元素;可用iterator遍历或get(index)随机访问特定元素;Queue:有序、可重复,允许多个null元素;先进先出,用于排队;Set:无序、不可重复,最多只能有一个null元素;只可用iterator遍历;Map:无序、key不可重复value可重复,允许一个key和多个value为null。
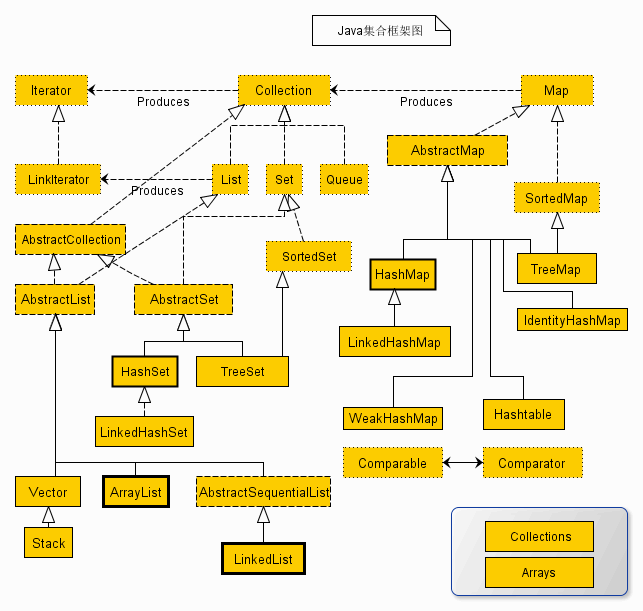
一、List 接口
ArrayList类CopyOnWrite(COW)并发容器CopyOnWriteArrayList:绝对线程安全,在读多写少的场合性能非常好,远远好于Vector;CopyOnWriteArraySet
LinkedList类Vector类Stack类:- 如
Stack<Integer> stack = new Stack<>() - 但一般用
Deque<Integer> stack = new ArrayDeque<>()来实现,效率更高。
- 如
二、Queue 接口
Deque双端队列接口:同时实现了栈和队列的功能;LinkedList类ArrayQueue类:Object[] 数组 + 双指针;
Pri'orityQueue类,优先级队列、非阻塞式:用 Object[] 数组实现二叉堆;BlockingQueue阻塞队列:非常适合用于作为数据共享的通道;并发- 广泛用在生产者-消费者模式:提供了可阻塞的插入和移除方法。当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
- 作为
workqueue参数传入构造器ThreadPoolExecutor()创建线程池; - 实现:
ArrayBlockingDeque类LinkedBlockingDeque类:同时实现了 Deque;
ConcurrentLinkedQueue: 高效的并发队列,是非阻塞队列,用链表实现。可看做线程安全的LinkedList。
三、Set 接口
HashSet类:实现了Set接口,存储对象;底层基于 HashMap、但有键无值;元素不可重复,最多只能有一个null元素;用add()添加元素、contains();LinkedHashSet类:(基于LinkHashMap、但有键无值,)有序(能按元素的添加顺序遍历);
TreeSet类:实现了Set和SortedSet接口;底层基于 TreeMap、但有键无值。
四、Map 接口
HashMap类:实现了Map接口,存储键值对;底层是 数组和链表(链表散列/链表数组,用于解决哈希冲突);键不可重复、值可重复,允许一个 key 和多个 value 为null;用put()添加元素、containsKey();比 HashSet 快(因为是使用唯一的键来获取对象);非线程安全;LinkedHashMap类:JDK1.8 后在解决哈希冲突时先进行数组扩容;ConcurrentHashMap类:线程安全的 HashMap,JDK1.8底层采用数组+链表/红黑二叉树实现。- 用 CAS 添加新节点,用 synchronized 锁定链表或红黑树的首节点。
- 唯一区别是其中的核心数据如 value 及链表都是
volatile(窝le滔)修饰的,保证了获取时的可见性;key 和 value 都不允许为 null。
ConcurrentSkipListMap: 跳表的实现。是一个 Map,用跳表的数据结构进行快速查找。
HashTable类TreeMap类:实现SortMap接口;基于红黑树(自平衡的排序二叉树)=>对8个包装类、String 根据 Key 自动升序(默认从大到小)排序,可定制排序方式;
| 集合类 | Key | Value | Super | 说明 |
|---|---|---|---|---|
| 1. HashMap | 允许一个为null | 允许为null | AbstractMap | 线程不安全 |
| 1.2 ConcurrentHashMap | 不允许为null | 不允许为null | AbstractMap | 分段锁技术 |
| 2. |
不允许为null | 不允许为null | Dictionary | 线程安全 |
| 3. TreeMap | 不允许为null | 允许为null | AbstractMap | 线程不安全 |
List中没有而ArrayList中独有的方法不能被List对象使用,即多态。
用多态方式调用方法时:先检查父类中是否有该方法,
- 如果没有,则编译错误;
- 如果有,再去调用子类的同名方法。
1 | |
线程安全
线程不安全的集合
注意,以下都是线程不安全的:
ArrayList, LinkedListHashSet, TreeSetHashMap, TreeMap
线程安全的集合
见多线程文档中#实现线程安全的方法#使用线程安全的集合、并发容器类。
使用线程安全的集合、并发容器类:
CopyOnWriteArrayListBlockingQueue、ConcurrentLinkedQueue、ConcurrentHashMap、ConcurrentSkipListMap、Collections.synchorizedList同步容器。
Collection 接口方法
- removeIf()
1 | |
List
ArrayList、LinkedList
二者都不是线程安全的。
- 底层实现方式:ArrayList 基于动态数组;LinkedList 基于双向链表(通过
getLast()源码可见为双向)。 - 按位查找:ArrayList 用
get(index)随机访问,快;LinkedList 指定位置 index 查找,效率为O(n),顺序访问。 - 插入和删除:ArrayList 效率受元素位置影响,对尾部增删O(1),指定位置 i 增删为O(n) ;LinkedList先查再增删,增删效率不受元素位置影响,均O(1)。
- 扩容机制:ArrayList 为新建数组并拷贝原数组;LinkedList 基于双向链表,不需要扩容。
- 内存空间:从单个元素说,LinkedList 空间开销大,需要保存前后节点的指针。
ArrayList 常用方法
1 | |
LinkedList 常用方法
1 | |
sort()
Comparator 排序比较器
- Comparator.comparing()
1 | |
Queue
-
offer()/add():一些队列有大小限制,在满的队列中加入新元素,调用 add() 抛出 unchecked 异常,调用 offer() 返回 false。 -
poll()/remove():都是从队列中删除第一个元素。用空集合调用时,remove()会抛出异常, poll() 只是返回 null,更适合易出现异常的情况。 -
peek()/element():都用于在队列的头部查询元素。在队列为空时, element() 抛出一个异常,而 peek() 返回 null。
Deque 双端队列
Deque 是一个比 Stack 和 Queue 功能更强大的接口,同时实现了栈和队列的功能。ArrayDeque 和 LinkedList 实现了 Deque 接口。
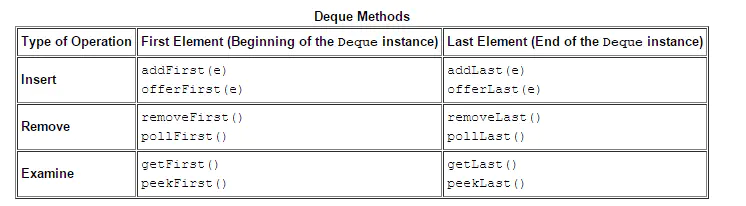
1 | |
hashCode()、equals()
hashCode():用于确定本对象在哈希表中的索引位置(如内存地址 => 整数),大大减少 equals() 的调用次数,从而提高效率。如 HashSet、HashMap 及 HashTable 等散列集合。
- 定义在
Object类中,意味着任何类(包括数组)都实现了此方法; - 是本地方法,即用 c/c++ 实现。
hashCode() VS equals()
两个对象相等(引用指向同一个对象,对象的内存地址相等):
<=>A.equals(B)返回 true,默认比较内存地址;=>两个对象 hashcode 相同:- 两个对象 hashcode 相同
=>A.equals(B)不一定返true=>对象不一定相等(哈希算法,散列,冲突); - 但两个对象 hashcode 不同
=>两对象一定不相等。
- 两个对象 hashcode 相同
重写 equals()
重写 equals() 时必须重写 hashCode():
- equals() 默认比较地址,
A.equals(B)返回 true表示二者地址相同,此时二者 hashcode 需相等(A、B 的 hashCode() 要返回相同的值); - hashcode 根据地址计算而来,equals() 重写后(一般不比较地址而比较内容)hashcode() 也需要重写;
- 如果没有重写,两个对象 hashcode 不同
=>两对象一定不相等(即使它们指向相同的数据)。
Set
两元素相等:判断标准和HashMap相同,两个元素的hashCode相等并且通过equals()方法返回true。
Set为何无序:基于哈希表存储,数组 + 链表 + 红黑树 + 哈希算法(链址法:CRUD性能都很好)
TreeSet 引用类型排序:
- 类重写比较器规则接口 Comparable;重写 compareTo() 或 compare();
- 直接为集合设置比较器 Comparable 对象,重写比较方法,二者都有时用集合。
Set 如何去重
Set 通过重写 hashCode 和 equals 实现去重。
调用 add() 添加元素时(用 HashMap 的 put() 实现,判断返回值为 true 以确保不重复),判断是否已有此对象?
- Set 用元素(HashMap 用 key)的内存地址计算 hashcode 值,判断 hashCode 是否已存在?
- 如不存在,则没有重复元素、直接插入;
- 若已存在,则用 equals() 判断两对象是否相等,比较地址(是否为同一对象?):
- 若二者不等则通过拉链法(附到链表数组的对应链表中)解决哈希冲突,插入成功,返回 true;
- 若相等则 Set 加入失败,返回 false(HashMap 直接覆盖,返回旧的 value 值)。
HashMap VS HashSet
HashMap比HashSet快,因为是使用唯一的键来获取对象
常用方法
1 | |
Map
HashMap VS HashTable
null:HashMap 允许一个key和多个value为null;HashTable 键值均不允许为 null,否则会抛出NullPointerException;- 线程安全:HashMap 是非线程安全的;HashTable 是线程安全的。
HashMap VS HashTree
HashMap 源码分析
Map 常用API
import java.util.HashMap;
import java.util.Map;
Map<String, Integer> maps = new HashMap<>();
//
maps.put("Java", 12);
maps.put(null, null);
Integer v = maps.get("Java");
maps.remove("Java");
maps.clear();
maps.isEmpty()
maps.size();
maps.containsKey("Java");
maps.containsValue(10);
//
Set<String> keys = maps.keySet();
for(String key : keys) {
System.out.println(key);
}
Collection<Integer> values = maps.values();
maps.putAll(maps2);
bool b = Double.compare(d1,d2);
MultiValueMap
MultiValueMap可以让一个key对应多个value,感觉是value产生了链表结构,可以很好的解决一些不好处理的字符串问题。
- 当然也可以用stringBuffer去拼,我觉得这个效果更好,效率更高。
1 | |
output:
1 | |
遍历集合
- continue 语句只能用在 while 语句、for 语句或 foreach 语句的循环体中。
可以用三种方法遍历集合:
1. For-Each 循环语句
JDK1.5 后推出,专门为集合遍历(获取元素)设计;效率最高。
1 | |
2. 迭代器
-
定义:提供一种方法访问容器对象各个元素,而又不需暴露对象的内部细节。实质是实现了用于遍历容器的hasNext()和next()方法
-
map不同于set和list,不是继承自Collection接口,没有实现Collection的Iterator 方法,自身没有迭代器来遍历元素。
1 | |
3. Lambda 表达式
JDK1.8后
objs.forEach(s -> {
System.out.println(s);
});
maps.forEach((K, V) -> {
System.out.println(k + "=>" + v);
});
// 如果添加的是默认收件地址,则将原默认地址修改为非默认
if (Boolean.TRUE.equals(createReqVO.getDefaultStatus())) {
List<MemberAddressDO> addresses = memberAddressMapper.selectListByUserIdAndDefaulted(userId, true);
addresses.forEach(
address -> memberAddressMapper.updateById(new MemberAddressDO().setId(address.getId()).setDefaultStatus(false))
);
}
// 4. 执行 TradeOrderHandler 的后置处理
List<TradeOrderItemDO> orderItems = tradeOrderItemMapper.selectListByOrderId(id);
tradeOrderHandlers.forEach(
handler -> handler.afterPayOrder(order, orderItems)
);
fail-fast 机制
如 ArrayList、HashMap 中。
区别:定义、原因
fail-fast(快速失败)机制:是 Java 集合的一种错误检查机制。当多个线程对集合进行结构上的改变的操作时,有可能会产生 fail-fast 机制。
- 原因:就在于程序在对 collection 进行迭代时,某个线程对该 collection 在结构上对其做了修改(而不是简单的修改集合元素的内容),这时迭代器就会抛出
ConcurrentModificationException异常信息,从而产生 fail-fast。 - java.util 包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)。
fail-safe(安全失败)机制:在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历,因此不会抛出java.util.ConcurrentModificationException异常。
- java.util.concurrent 包下的集合都是 fail-safe 的,可以在多线程下并发使用,并发修改。
- 有两个问题:
- 需要复制集合,产生大量的无效对象,开销大。
- 无法保证读取到的数据是目前原始结构中的数据。
解决方法
有两种解决方案:
- 在遍历过程中所有涉及到(改变 modCount 值的地方)全部加上
synchronized或者直接使用Collection synchronizedList。但是不推荐,因为增删造成的同步锁可能会阻塞遍历操作。 - fail-safe 机制:使用
CopyOnWriteArrayList替换 ArrayLIst。推荐使用该方案。- CopyOnWriteArrayList 是 ArrayList 的一个线程安全的变体,绝对线程安全,其中所有可变操作(add、set 等)都是通过对底层数组进行一次新的复制来实现的。
- 该类产生的开销比较大,但是遇到两种情况,非常适合使用来替代 ArrayList。
- 在不能或不想进行同步遍历,但又需要从并发线程中排除冲突时。
- 当遍历操作的数量大大超过可变操作的数量时。
Collections 工具类
都是静态方法
1 | |