摘要:1. 基本语法、常量和变量(final、static 关键字)、数据类型、面向对象(封装、继承、多态、接口); 2. 异常、泛型、反射、注解; 3. IO和序列化、Socket 网络编程、Stream 流、JDK 新特性; 4. 常用类。
目录
[TOC]
Java、C++
- 纯面向对象的语言(封装、继承、多态)-> 低耦合的系统,易维护、复用、扩展;C++ 兼容 C,效率高但有面向过程。
- JVM:跨平台/平台无关,一次编译到处运行(很好的可移植性),字节码运行机制,既有编译又有解释;C++为编译型语言,C++11 Windows 下无法静态初始化数组。
- JVM:自动内存管理,没有指针(除
Unsafe类),更安全、方便;C++ 要手动释放内存,虽然可自由管理内存,但指针易导致:- 野指针(指向垃圾内存的指针):没有初始化直接使用而导致野指针;free 或 delete 后没有置为 NULL,当做合法指针使用导致野指针;
- 空指针 NPE;
- 内存泄漏。
- Java 集合容器更完善。
- 多线程:支持多线程;C++ 没有内置的多线程机制,必须调用 OS 的多线程功能。
- 支持网络通信编程且很方便,支持 Web 应用开发。
- Java 相对于 C、C++有着丰富的类库和三方框架。
JDK、JRE、JVM 对比
JDK(Java Development Kit),是一种功能齐全的 Java SDK,用于程序开发者创建、编译程序。
- Java 开发组件:
javac编译器、jar打包工具、javadoc文档生成器、java-debuger(jdb)调试工具、javap -c反汇编; JRE(JAVA Runtime Environment):包含普通用户运行 Java 程序所需的全部内容。JVM(JAVA Virtual Machine):是一个用于执行Java 字节码的虚拟机进程,针对不同系统有特定的实现;实现一次编译,到处运行;如HopSpot、JRockit、J9Vm;- 用于产品环境的 Java 类库。
Oracle JDK、OpenJDK
基本语法
关键字
注意:
- 虽然
true、false、null看起来像关键字,但实际上是字面值/量,同样也不可作为标识符。 - 标识符
var、yield和record是受限标识符,因为在某些上下文中是不允许的。 instanceof关键字:若对象为类(或接口、抽象类、父类)的实例,则返回 true。
访问控制符
见接口新增三个方法。
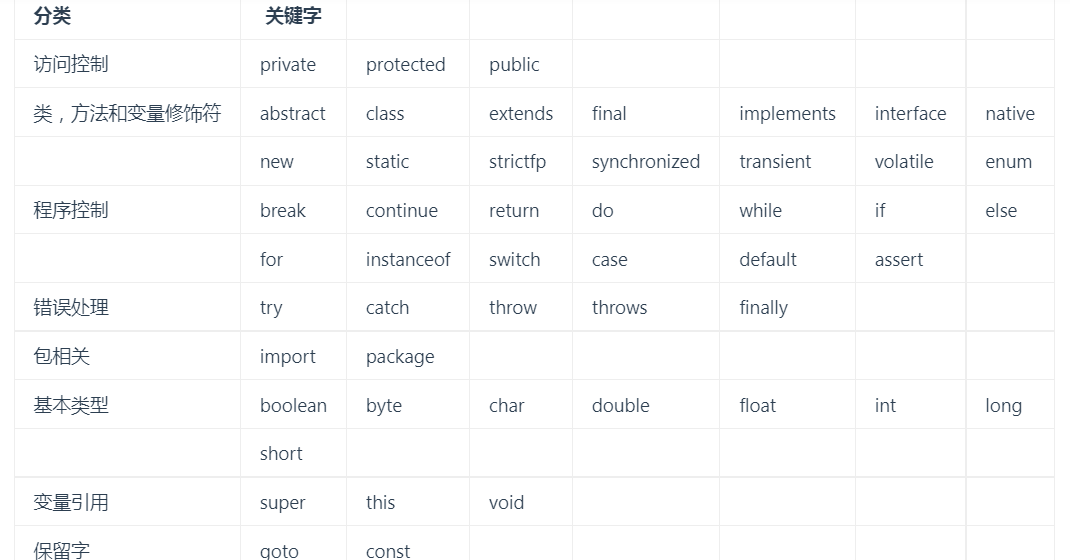
访问控制符:private、default、protected、public
public: 对所有类可见。protected: 对同一包内的类和所有子类可见。可以访问不同包的、从基类继承的 protected 变量、方法。- 子类与基类在同一包中:被声明为 protected 的变量、方法和构造器能被同一个包中的任何其他类访问;
- 子类与基类不在同一包中:那么在子类中,子类实例可以访问其从基类继承而来的 protected 方法,而不能访问基类实例的protected方法。
default(即默认,什么也不写):在同一包内可见(只能访问同一包中的子孙类),不使用任何修饰符。private: 在同一类内可见。
| 修饰符 | 使用对象 | 当前类 | 同一包内 | 子孙类(不同包) | 其他包 |
|---|---|---|---|---|---|
public |
类、接口、变量、方法 | Y | Y | Y | Y |
protected |
变量、方法,不能修饰类(外部类) | Y | Y | Y/N(说明),可以访问从基类继承的 | No |
default |
类、接口、变量、方法 | Y | Y | No | No |
private |
变量、方法,不能修饰类(外部类) | Y | No | No | No |
常量和变量
成员变量 VS 局部变量
静态成员变量、非静态(实例)成员变量,局部变量(本地变量)
- 定义(本质):
- static 成员变量属于类,用类名调用,由类的所有对象共享,持久驻内存(方法区),下次调用保留原值;
- 非 static 成员变量属于对象,用对象名调用;
- 局部变量是在代码块/方法中定义的变量/方法参数。
- 存储位置:
- static 成员变量属于类(即静态变量/类变量),存于方法区,
- (非 static )成员变量属于对象,存于堆内存;
- 局部变量属于方法,存于 VM 栈中的局部变量表,基本类型变量直接存值,对象存放引用,指向堆内存中的对象本身。
- 默认值/初始化时机:
- 成员变量有默认值,在 JVM 类加载时自动初始化(如未赋初值则取默认值)(例外:被 final 修饰的成员变量必须显式地赋值);
- 而局部变量(不自动初始化)必须显式地初始化,在字节码执行时才会运行方法中的(局部变量)代码。
- 生命周期:成员变量与类/对象一致;局部变量与方法一致。
- 修饰符:成员变量都可以;局部变量不能被访问控制修饰符及 static 修饰,只能被 final 修饰。
1 | |
final 关键字
final 核心思想:最终的、不可修改的;表示变量值不可变、方法不可覆盖、类不可继承。
一、修饰类
修饰类:不可被继承(没有子类):
- final 修饰的类,所有成员方法被隐式指定为 final,(但成员变量不变);
- 所有包装类和 String 类都是用 final 修饰的;
- final 不能修饰 abstract,二者互斥、冲突、不能同时存在;
1 | |
二、修饰方法
修饰方法:不可重写,可重载。
作用:
- 用于防止子类覆盖父类方法的实现,保证安全;如:POJO 类的 setter 方法,不允许被覆写。
- 方法被转为内嵌,提高执行效率。
private 方法都被隐式指定为 private [final] ;
- final 也可修饰 private,但无意义。
三、修饰变量
修饰变量:值不可变。 => 成为常量。
实质上是常量。JDK1.8 后改为存放在堆内存中。
从变量类型分类
- 修饰基本类型或
final String类型的变量:使用前必须有且仅有一次初始化,初始化后值不可变;- 第二次赋值将抛出编译时错误(
Compiler Error: cannot assign a value to final variable)。 - 若编译阶段已知其确切值,则会当做编译期常量(直接宏替换),存入调用类的运行时常量池中(方法区)。
- 第二次赋值将抛出编译时错误(
- 修饰引用类型变量:初始化后引用不可变(即不能指向另一个对象),但引用指向的对象的内容可变。即 final 数组 / String 类 / 集合内可添加、删除元素。
从变量位置分类
- 修饰静态成员变量(类变量)=> 即静态常量:只可在静态初始化块中/声明时赋初值;作用域是全局,不用创建对象,用类名直接访问;
- 修饰(实例)成员变量 => 即成员常量:只可在非静态初始化块中/声明时/每个构造器中赋初始值;
- 修饰局部变量 => 即局部常量:使用前赋值,不允许二次赋值。
// 访问静态常量
HelloWorld.PI;
public class HelloWorld {
// 修饰静态变量,即静态常量
public static final double PI = 3.14;
// 修饰成员变量,即成员常量
final int Y = 10;
public static void main(String[] args) {
// 修饰局部变量,即局部常量
final double X = 3.3;
}
}
-
在
foreach语句中可用final声明存储循环元素的变量; -
局部内部类和匿名内部类只能访问局部常量:因为外部类运行后局部变量会被回收,内部类延长局部变量 copy 的生命周期、用
final保证二者一致。JDK1.8后默认加 final。
static 关键字
static 修饰的成员属于类,可被类的所有对象共享,加 static 不影响作用域。
- 只保存一份拷贝,可用类名调用。
一、修饰成员方法(=> 即静态方法、类方法)
不依赖任何对象,在类加载时(在方法区)分配内存,可通过类名直接访问;
- 只能访问类的静态成员(变量或方法):因为非 static 成员在对象实例化前不存在,不能被 static 方法调用;
- 方法中不能以任何方式引用 this 和 super;但反之在非静态方法中可通过 this 访问静态成员;
方便在没有创建对象的情况下调用方法/变量,如:
- Collections 类中的一些方法,如
Objects.equals(); - Hutool util 工具类中的方法,如 Math 工具类、Arrays 工具类的静态方法;
- 单例模式的
getInstance()、工厂模式的create/build()、日志Logger LOGGER = LoggerFactory.getLogger(Users.class)等。
构造器不是静态方法
- 定义:(严格意义上)不是方法,只负责初始化;
- this:构造器中可使用this(指向当前对象),而静态方法不依赖任何对象;
- 调用:构造器只能通过 new(或别的构造器)调用,不能通过方法调用。
二、修饰成员变量(=> 即静态变量/类变量)
实质上就是全局变量;
目的:作为共享变量使用;减少对象的创建;保留唯一副本。
- 定义:static 成员变量属于类,用类名调用,由类的所有对象共享,持久驻内存(方法区),下次调用保留原值;
- 存储位置/内存分配:static 成员变量属于类,存于方法区,(非 static )成员变量属于对象,存于堆内存;
- 默认值
- 生命周期:从类被加载开始,到类被 GC 彻底回收时。
三、静态代码块
执行顺序:静态代码块 –> 非静态代码块 –> 构造器。
定义在类中(方法外),用于初始化静态变量:不管创建多少对象,静态代码块都只执行一次;
- 对于定义在它之后的静态变量,可赋值,但不能访问。如单例模式、定义枚举类。
非静态代码块与构造函数的区别:
- 非静态代码块是对所有对象进行统一初始化,而构造函数是给当前对象初始化。
四、静态内部类
static 只能修饰内部类。
非静态内部类在编译完成后会隐含地保存一个引用,指向创建它的外部类,但静态内部类没有。意味着:
- 创建对象不依赖外部类创建的对象,可直接通过外部类创建;
- 不能使用任何外部类的非 static 成员变量/方法。
如:AB-BA 死锁问题。
静态内部类用于定义 DTO 传参。
1 | |
五、静态导入包
1.5 后的新特性, 格式为:
import static;
可导入某个类中的指定静态资源,不需用类名即可直接调用(类中的)静态成员变量/方法等。
final VS static 变量
1 | |
数据类型
基本数据类型和引用类型的区别主要在于:
- 基本数据类型是分配在栈上的,而引用类型是分配在堆上的。
四大类八小类基本数据类型
基本数据类型都是直接存储在内存中的 Java 虚拟机栈上的。
primitive type,所占空间大小,默认值,取值范围。
基本数据类型对应的包装类型。
- 布尔型
boolean占用大小根据实现 JVM 不同有所差异,官方手册没有明确说明,逻辑上占1Byte:- 根据《Java虚拟机规范》里的结论,如果boolean单独使用、最终被编译为 int 类型,则占4字节;如果以boolean数组使用、最终会被编码为 byte 数组,则占1字节;
- 默认值 false:不能转换成任何数据类型,true != 1;
- 字符型
char2Byte ‘u0000’:0 ~ 65535. - 4种整型:
byte即字节,1Byte 默认值0:取值范围-128~127;short2Byte 0:2^15-1 = 32,767;int4Byte 0:2^31-1 = 2,147,483,647(21亿);long8Byte 0L:BigInteger类。
- 2种浮点型:
float4Byte 0F:double8Byte 0D:
1 | |
三类引用数据类型
reference type
引用类型继承于Object类(也是引用类型),都是按照Java里面存储对象的内存模型来进行数据存储的:
- “引用”(存放对象在内存堆上的地址)是存储在VM栈上的,而对象本身的值存储在内存堆上的。
用作方法的参数和返回值的类型。
- 数组
- 类
- 接口
包装类
包装类(wrapper class),箱子;
- 为了方便基本数据类型能和其它对象结合在一起使用,
- 如一些常用的集合
List和Set等要求存放的值必须为对象。
都是用 final 修饰,无法继承。
包装类型
基本数据类型对应的包装类型,及其放入(方法区中运行时)常量池的取值:
Boolean:TRUE/FALSE两个常量,用于表示布尔值true 和 false;Boolean.TRUE.equals(createReqVO.getDefaultStatus())
Character:[0, 127],即7位ASCII码、最大7F Del;Byte Short **Integer** Long:[-128, 127];Float、Double:不会进入常量池;String类型:所有字面量都会进入常量池;
常量池缓存机制
包装类在常量池的值会复用已有对象的缓存数据,可直接用 == 判断;其它范围的值,必须全部用 equals() 比较。如:
- 对于
Integer var = 40在 -128 至 127 间的赋值,会自动装箱(转为包装类对象),Integer 对象通过IntegerCache.cache产生,会复用(缓存中的)已有对象;此区间外的所有数据都在堆上产生,不复用已有对象。 - 而通过 new,如
Integer i2 = new Integer(40)会直接创建新对象(手动装箱)。
基本数据类型 VS 包装类型
区别:
- 根本:一种数据类型;一种引用数据类型(面向对象的类),有类的特性(封装、继承、多态等)。
- 存储位置:
- 基本数据类型定义的变量,用作局部变量(直接存放在 VM 栈的局部变量表中,占用空间小),用作
static成员变量(存放在方法区),用作非static成员变量(存放在堆中); - 而用包装类实例化的对象,一律存放在堆中。
- 基本数据类型定义的变量,用作局部变量(直接存放在 VM 栈的局部变量表中,占用空间小),用作
- 默认值:基本数据类型有默认值(int = 0)且不是
null;包装类型若不赋值则为null。 - 泛型:基本类型不可用于泛型;包装类型可以。
自动装箱/拆箱机制
从 JAVA SE5 开始引入自动装箱/拆箱机制 -> 将基本数据类型当成(对应包装类的)对象操作,使二者可方便的相互转换(一种面向对象的体现):
- 装箱:将基本数据类型 ==> 转换为对应的包装类型;
- 拆箱:将包装类型 ==> 转换为对应的基本数据类型;
自动拆箱的时机:
-
将包装类型变量直接赋值给对应基本数据类型时;
-
当要访问包装类对象的真实数据值时,如进行数学运算、比较大小、输出对象的值、三目运算符数据类型对齐。
缺点:
- 频繁装箱/拆箱,会严重影响系统的性能,应尽量避免不必要的装箱/拆箱操作。
-
自动拆箱可能导致 NPE,需进行 NPE 检查。见下三目运算符。
- 手动装箱:
Integer.valueOf(128) - 手动拆箱:
变量.intValue()
- 手动装箱:
// 装箱
Integer i1 = new Integer(128); // 手动装箱,基本数据类型 => 堆内存中的包装类对象
Integer i2 = 128; // 自动装箱,调用 Integer.valueOf(128); Double、Float的valueOf()类似
// 比较包装类对象
i1 == i2? // false,比较引用,常量池外的值不复用,两个不同对象的地址不同;若为[-128, 127],则复用已有对象,地址相同,返回true
i1.equals(i2)? // true,不同对象的值相等
// 拆箱
int i3 = i2.intValue(); // 手动拆箱,包装类对象 => 基本数据类型
int i3 = i2; // 自动拆箱,调用 i2.intValue()/xxxValue()
// 初始值为不可达到的长度,s.length() + 1 也行
int subStrMinLen = Integer.MAX_VALUE;
与字符串间的转换
继承自 Object 类的方法:
1 | |
数据类型转换
自动类型转换:系统把某种基本类型的值直接赋给另一种基本类型的变量。
-
char => int -> long -> float -> double; byte -> short => int -> long -> float -> double;
强制类型转换:把一个范围大的数值或变量赋给另一个范围小的变量。如将 float 类型的变量赋值给 int 变量。
- 下转型(down-casting,也称为窄化)会造成精度损失;
-
条件表达式(三目运算符)
condition ? 表达式1 : 表达式2中,表达式1 和 2 在类型对齐时,可能抛出因自动拆箱(和强制类型转换)导致 NPE 异常。如表达式 1 或 表达式 2 的值:- 任一个是基本数据类型;
- 类型不一致,会强制拆箱升级成表示范围更大的那个类型。
1 | |
运算符 ==、equals()
都用于比较是否相等。区别:
- 引用相等:指的是变量指向的内存地址相等,用
==比较; - 对象相等:指的是内存中存放的内容相等,用
equals()比较;
运算符 ==
== 比较的是变量指向的内存地址是否相等,即引用是否相等。
对于 ==,因为 Java 只有值传递,所以不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。
- 用于基本数据类型,直接比较其(vm 栈中)存储的值是否相等;
- 用于引用类型,比较两个引用是否指向同一个对象/同一块堆内存地址;
- 除非是同一个
new出来的对象,或经过赋值指向同一个对象,或(在字符串常量池中)指向同一块内存地址,才为 true,否则为 false。因为每 new 一次,都会重新开辟堆内存空间。 null == null:返回 true,null 既不是对象也不是一种类型,仅是一种特殊的值;- 比较 String 变量:
==比较的是内存地址,equals()比较的是值; - 比较对象:
==和equals()比较的都是内存地址,没有重写equals()方法的类都是调用的 Object 的equals()方法。
- 除非是同一个
- 表达式(包含算术运算)== 包装类(触发自动拆箱 => 基本数据类型):比较的是数值。
1 | |
不能用 == 比较大小的
- 基本类型的变量、值 == 引用类型(包装类)的变量、值;不能触发自动拆箱;
- boolean 类型的变量、值 == 其他任意类型的变量、值;
- 没有继承关系的两个引用类型之间:
- 包装类之间:如果用,则比较的是变量指向的引用/内存地址是否相同,应该用equals() 比较两个对象的内容是否相同;
- 浮点数之间:若浮点数之间用
==比较,会有浮点数精度陷阱,不精确;可以设置误差范围,或见 BigDecimal 类。
equals()
equals() 用来比较两个对象(内存中)的内容是否相同,即对象是否相等。
- 不能用来比较两个基本数据类型的变量,应该用
==; - 对于引用类型:
- 若没重写 equals()
==>equals() 继承自Object类,故每个对象都有 equals(),Object 中默认(直接调用==)对比两个对象的地址是否相等; - 多数情况下,重写 equals()
==>比较对象存储的内容是否相等。如 String类、包装类、Date类等;
- 若没重写 equals()
1 | |
重写 equals()
见 Java 集合框架文档中的 hashCode() VS equals() 部分。
重写 equals() 必须重写 hashCode():保证 equals() 相同的对象哈希码也相同。
equals() 和 hashCode() 同时存在的意义:
equals()保证可靠:比较对象(地址或内容)是绝对相等的;hashCode()保证性能:用于获取哈希码(确定该对象在哈希表中的索引位置),通常用来将对象的内存地址转换为整数后返回;- 保证在最快的时间内判断两个对象是否相等,可能有误差值;
- 同一对象的 hashcode 一定相等,不同对象的也可能相等。
否则违背了【两个相等的对象必须有相等的哈希码】这一 Java 关键约定,进而影响散列表、HashMap 等。
- 因为 Set 存储的是不重复的对象,依据
hashCode()和equals()进行判断,所以 Set 存储的对象必须覆写这两种方法。 - String 因为覆写了
hashCode()和equals()方法,所以可以愉快地将 String 对象作为 key 来使用。
String 变量中的应用
1 | |
数组
用法
- 声明:只得到一个存放数组的变量,并没有为数组元素分配内存空间;
- (用 new 关键字)分配内存空间;
- 初始化;
- 使用。
1 | |
当指定的下标值超出数组的总长度时,会拋出 ArrayIndexOutOfBoundsException(数组越界异常)。
因为 Java 类与类间支持继承,可能产生一个数组里可存放多种数据类型的假象。
- 如一个水果数组,元素可是苹果或香蕉(都继承了水果),但元素类型还是水果。
数组、List、ArrayList
- 数组:大小固定,查找快;
- List:是接口;
- ArrayList 类:是 List 的实现类,有序,以一定的顺序保存元素。
Array 类和 Arrays 工具类
Array 类:提供静态方法,动态创建和访问数组。
1 | |
Arrays 类:提供静态方法,对数组进行操作。定义在 java.util 包中,主要实现数组元素的查找,内容填充、排序等。
- 其它工具类见 常用类。
1 | |
面向对象
Object Oriented
对象
根据 JVM 规范:”对象是动态分配的类实例或数组”。实例是内存中的对象。
抽象:指将一类对象的共同特征提取出来构造类,类是对象(实例)的抽象。一切皆对象。
1 | |
面向对象
面向对象和面向过程的主要区别在于:解决问题的方式不同;
- 面向过程:把解决问题的过程拆成一个个方法并执行;
- 面向对象:先抽象出对象,用对象执行方法的方式解决问题。一般更易维护、复用、扩展。如包装类,一切皆对象。
见面向对象思想文档。
面向对象思想主要包括:
- 三大特性:封装、继承、多态。
- UML 类间关系(数据库中):
- 实现关系
---△ - 泛化关系
——△ - 聚合关系
——◇ - 组合关系
——◆ - 依赖关系
---> - 关联关系
——>——
- 实现关系
- 设计原则(设计模式中)S.O.L.I.D
- S 单一职责
- O 开闭原则
- L 里氏替换
- I 接口隔离
- D 依赖倒转
D 迪米特原则- H 合成/聚合复用
封装、继承、多态
封装
定义:利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。
- 控制对外隐藏和暴露哪些数据:
- 指把对象的成员变量/属性隐藏在内部,不允许外部对象直接访问,
- 通过(可被外界访问的)public 方法来操作属性。
- 基本单位是类。如 POJO 类的 getter/setter 方法。
优点:
- 减少耦合:可以独立地开发、测试、优化、使用、理解和修改
- 减轻维护的负担:可以更容易被理解,并且在调试时可以不影响其他模块
- 有效地调节性能:可以通过剖析来确定哪些模块影响了系统的性能
- 提高软件的可重用性
- 降低了构建大型系统的风险:即使整个系统不可用,但是这些独立的模块却有可能是可用的
继承
继承:指子类可使用父类的所有属性和方法。子类 is a 父类。
继承的特点:
-
子类拥有父类所有的属性和方法(包括私有属性和私有方法),但无法访问父类中的私有属性和方法,仅拥有。
- 子类不能继承父类的构造器;
- 子类可重写父类的方法;继承应该遵循里氏替换原则,子类对象必须能够替换掉所有父类对象。
- 继承后变量和方法的访问顺序:就近原则。
-
单继承(不支持多重继承):程序结构更清晰、便于维护。多重继承会使类型转换、构造方法的调用顺序变复杂,影响性能。
- 若支持多重继承:类 C 继承自类 A 和类 B,如果类 A 和 B 都有自定义的成员方法 f(),则调用类 C.f() 会产生二义性;
- 通过实现多个接口、间接支持多重继承:接口由于只包含方法定义,(不能有方法的实现),类 C 不能直接调用方法,需实现具体的 f() 才能调用,不会产生二义性。
-
对于父类的包访问权限、成员变量/方法,如果子类和父类在同一个包下,则子类能继承,否则子类不能继承;
方法重载 VS 重写
- 重载(overload):同一个类中,多个同名方法(根据不同的传参)执行不同的逻辑处理;
- 重写/覆盖、覆写(override):子类继承父类已有的方法,并重新实现其内部逻辑、功能。遵循两同两小一大。
区别:
- 方法名都相同。
- 发生范围:重载在同一个类;重写在子类中。
- 参数列表(类型、个数、顺序) :重载至少一个不同;重写一定相同。
- 返回值类型、异常:重载可不同(只有返回值不同不算重载);两小:重写子类的返回值类型、异常范围(
RunTimeException)<= 父类(Exception)。 - 访问修饰符:重载可不同;一大:重写,子类访问权限(只能是
public,而非private)>= 父类(protected),即子类修饰符不能做更严格的限制;- 另外父类方法修饰符为
private/final/static或构造器时(都不能被继承),子类不能重写,但被 static 修饰的方法能被再次声明。 - 反射机制。
- 另外父类方法修饰符为
- 发生阶段:重载实现的是编译时的多态性(即前绑定);重写实现的是运行时的多态性(即后绑定)。
this、super 关键字
this 代表当前类对象的引用,指向本对象;super 代表对父类对象的引用,指向父类对象。
- 在构造器中,this用于区分(同名)成员变量与局部变量;
- this 调用本类中的其他构造方法、super() 调用父类中的其他构造方法时,必须处于构造器的首行,否则编译器会报错。
- 在 static 方法中,this、super 不可用。
super 用于继承,主要用法:
super.成员变量/方法:用于在子类中,调用父类的同名成员变量或方法;super(param1, ...):用于在子类构造器(的第一行),显式地调用父类构造器;- 若父类有无参构造器,系统会自动调用
super(); - 若父类的构造器都带参,则必须用
super(param1, ...)显式调用一次。
- 若父类有无参构造器,系统会自动调用
多态
多态:即一个接口,多个方法。
- 指多个子类继承并重写父类的同一属性或方法,
- 或多个子类实现接口并覆盖接口中的同一方法,并将父类引用指向子类对象。
1 | |
3 个必要条件
实现多态有 3 个必要条件:
- 子类继承父类/实现接口;
- 方法重写;
- 父类引用指向子类对象(向上转型)或接口的引用变量指向其实现类的实例对象。
分类
- 编译时多态:是静态的,主要指方法重载。编译后变成不同的方法;
- 运行时多态:是动态的,即通常所说的多态性。指程序中定义的对象引用所指向的具体类型在运行期间才确定。
- 指继承父类和实现接口时,可用父类引用指向子类对象。
- 引用类型变量发出的方法调用的到底是哪个类中的方法,必须在程序运行期间才能确定。
特征
- 对于方法的调用:编译看左边,运行看右边?
- 如果子类重写了父类方法,真正执行的是子类覆盖的方法;
- 如果子类没有覆盖父类的方法,执行的是父类的方法。
- 对于变量:编译、运行都看左边。
优缺点
优势:
- 父类作为方法的形参(入参)用来传递对象;
- 便于类与类间解耦,右边对象可组件化切换,改换业务。
劣势:
- 编译看左边,不能调用子类独有的方法。
值传递 VS 引用传递
Java中没有指针的概念,类似的是引用。
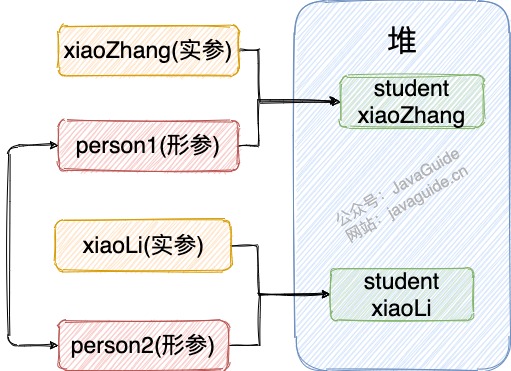
Java 中方法参数的传递方式是值传递:
- 值传递:将实参的(引用、浅、深)拷贝副本传递给 Java 方法的形参;方法对拷贝副本的修改不会影响实参值。
- 参数是基本类型时:传递的是基本类型的字面量值的拷贝,会创建副本;
- 参数是引用类型时:传递的是实参(所引用对象在堆中)地址值的拷贝(浅拷贝?),同样也会创建实参的副本(形参);
- 方法可修改引用指向的对象内的属性(状态),但这仍是按值调用而非引用调用。
- Java 中有三种类型的对象拷贝:引用拷贝、浅拷贝 vs 深拷贝。?
- 引用传递:实参所引用的对象(在堆中)的内存地址传递给方法的形参。
- 不会创建副本,修改形参将影响实参。
- 如,C++ 的指针。
交换 String 对象的内容:
1 | |
引用拷贝、浅拷贝 vs 深拷贝
Java 中有三种类型的对象拷贝:
- 三者在变量、引用的对象本身、引用的对象内部的对象属性逐次递进地创建副本。
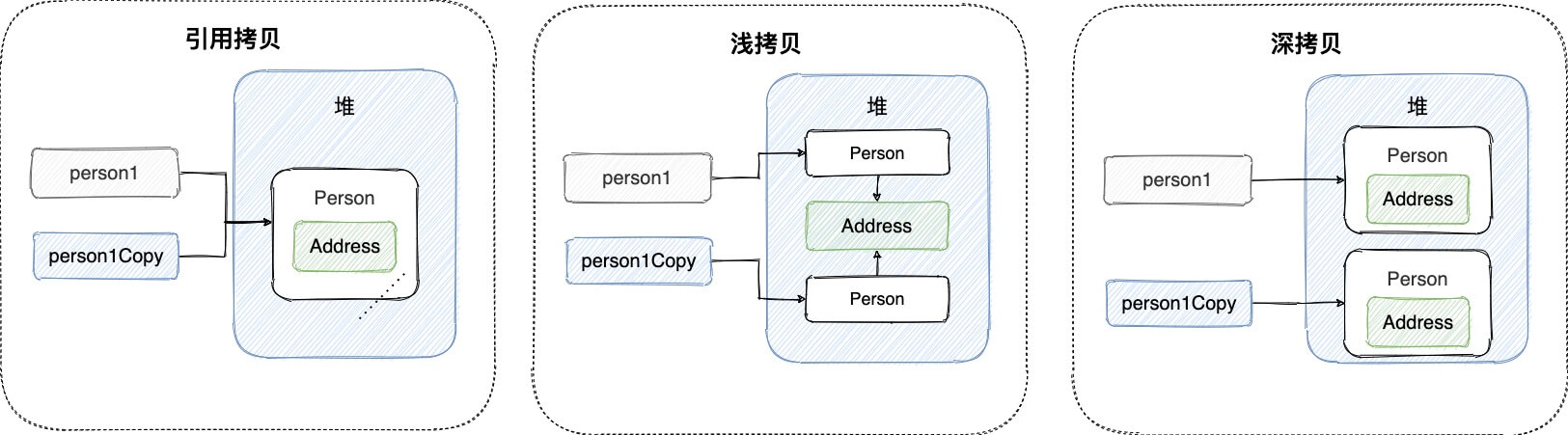
引用拷贝
引用拷贝:在栈中创建一个变量副本,存储原变量所引用的对象(在堆中的)地址,不会创建对象副本。
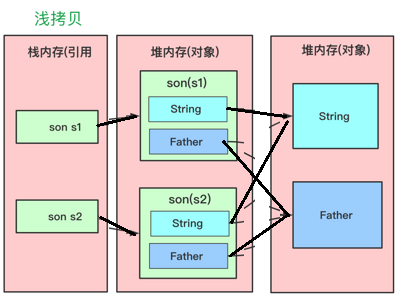
浅拷贝
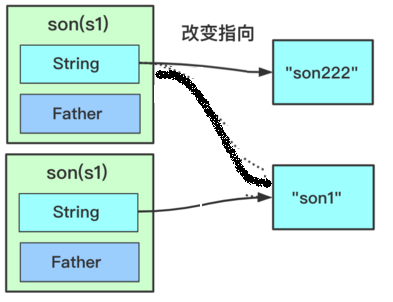
浅拷贝(Shallow Copy):在堆上创建一个原变量所引用的对象的副本,可修改对象副本内部的属性:
- 基本数据类型的变量,直接拷贝变量值(创建属性副本);
- 引用类型的变量,创建对象副本并存储原内部引用的地址,不复制内部引用指向的对象本身。即拷贝对象和原对象共用同一个内部对象。
实现方法:在当前类中实现 Clonable 接口、并重写 Object 类的 protected clone(),在方法内直接调用父类的 clone() 方法,即 return super.clone()。
1 | |
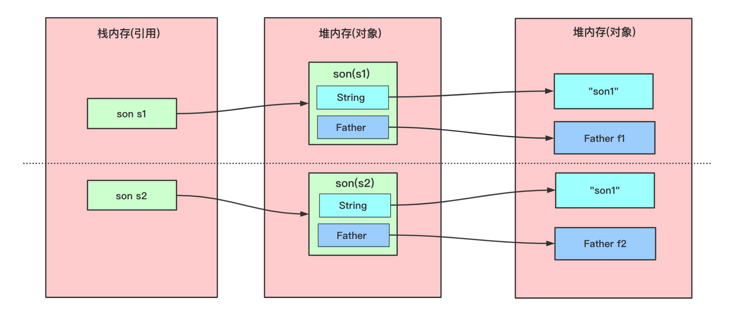
深拷贝
深拷贝(Deep Copy):深拷贝会完全复制整个对象,包括对象所包含的内部对象。比浅拷贝速度慢且花销大。为对象内的所有数据均创建副本:
- 对基本数据类型,直接创建并复制值;
- 对引用数据类型,创建一个对象副本并复制(new)其内部的成员变量。
通过序列化来实现深拷贝:适用于引用数量或层数太多时,原对象写入文件后拷贝给 clone 对象。
- 修改原对象不会影响 clone 对象,因为 clone 对象是从这个媒介读取。
实现方法:在当前类中实现 Cloneable 接口并重写 clone(),在方法内 new 一个当前类的新对象,即 return new Student(name, subj.getName()); 。
1 | |
延迟拷贝
延迟拷贝(Lazy Copy):二者组合
接口
接口(interface)是用来被实现的(implements 实现类),没有构造器。
- 类与类单继承;
- 接口与接口多继承;
- 类可实现多个接口;
新增三个方法
JDK1.8 前接口中只有:
- 默认为抽象方法
public abstract; - 常量。
JDK1.8 后新增三个方法:
- 默认方法:用
default修饰,即实例方法; - 静态方法:只能用接口名本身调用,不能用子接口/实现类调用;
- 私有方法:被私有方法/默认方法调用,只能在本接口中访问。
1 | |
抽象类
抽象类(abstract class):包含抽象方法的类,不能用来创建对象。
- 抽象方法:只有声明,没有具体的实现。
- 有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法。
- 类继承抽象类或实现接口,要实现所有抽象方法,否则仍需被声明为抽象类。
抽象类的意义(代码复用):
- 为了被子类单继承;
- 模板设计模式(部分实现,部分抽象)。
抽象类 VS 接口
同:
- 都不能直接例化,(但可定义抽象类和接口类型的引用):(接口的实现类或抽象类的子类)需实现相应的方法后才能被例化。
- 都可包含抽象方法。
- 都可有默认实现的方法(Java 8 可用
default关键字在接口中定义默认方法)。
异:
- 定义:抽象类被设计用来被继承的(用于代码复用),接口被设计用来实现的。
- 一个类只能继承(extends)一个抽象类,但可实现(implements)多个接口。
- 构造器:接口比抽象类更抽象:抽象类可有静态方法、静态代码块、构造器;接口中 JDK1.8后可有静态方法,没有构造器。
- 成员变量:抽象类可定义成员变量,默认 default,可在子类中被重新定义,也可被重新赋值;接口中的成员变量只能用
public static finial修饰(JDK1.8 后默认为default),实际是常量,不能被修改且必须有初始值。 - 方法:抽象类可有(普通成员)方法的具体实现;接口(只有
public abstract方法定义,)不能有方法的具体实现。 - 修饰符:抽象类中的方法可用
private, protected, public修饰;接口只能用public。
内部类
- 静态内部类:作为外部类的静态成员。
public static,只加载一次,寄生和宿主的关系;只能访问外部类的静态成员。 - 成员内部类(实例内部类):作为成员对象的内部类。
- 可访问(private及以上)外部类的属性和方法。
- 外部类想访问内部类属性或方法时,必须通过创建的内部类对象访问。外部类也可访问内部类属性。
- 实例内部类对象属于外部对象,是外部对象实例化的成员变量;没有静态区,不能定义静态成员,能定义常量;
Outter.Inner o = new Outter().new Inner(); - 能访问外部类的静态成员和实例成员。
局部内部类:几乎不用。方法中的内部类。只能定义实例成员,不能定义静态成员。访问权限类似局部变量,只能访问外部类的final变量。- 匿名内部类:没有类名的局部内部类,只能用一次,只能访问外部类的final变量。new子类时重写父类的抽象方法可省略子类定义,立即返回匿名内部类对象;用于对象回调、创建接口对象来简化代码。
可变长参数
- 在方法内部本质是一个数组。
- 只允许一个可变参数,只能放在最后。
- 方法重载会优先匹配固定参数的方法,因为固定参数的方法匹配度更高。
1 | |
异常
异常分类
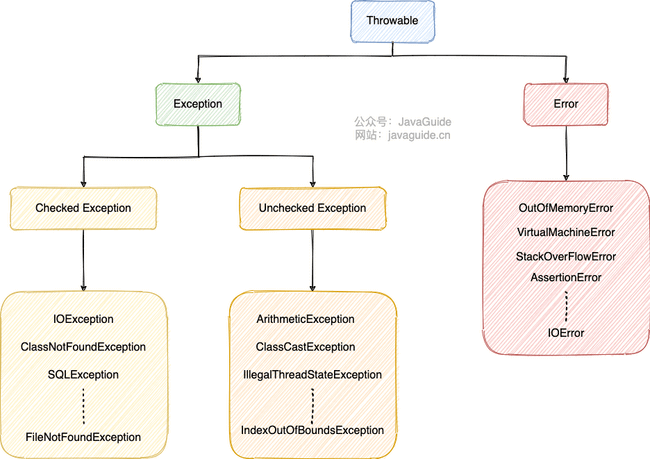
顶级父类 java.lang.Throwable:将异常层层抛给顶层,统一处理。
Error
Error:程序无法处理的错误,无法通过 catch 捕获,只能尽量避免。发生时 JVM 一般会终止线程。
Java Virtual Machine Error:JVM 运行错误。OutOfMemoryError:OOM 内存溢出,见 JVM 文档。StackOverFlowError:栈溢出。NoClassDefFoundError:类定义错误。AssertionErrorIOError
Exception
Exception:程序本身可处理的异常,可通过 try-catch 捕获。包括:
Checked Exception
checked exception(编译时、受检查异常):代码还没运行,编译器就会检查,并要求必须处理的异常;如果不处理,程序就不能编译通过。
除了RuntimeException及其子类以外都是 checked exception。必须要对这段代码 try...catch,或 throws exception。
IOExceptionClassNotFoundException:如果 JVM 在反序列化时找不到该类,则抛出此异常。SQLExceptionInterruptedException:线程被另一个线程中断;IllegalAccessException:访问类被拒绝;NoSuchMethodException:通过反射机制调用的方法不存在;- 及用户自定义的 Exception 异常。
Unchecked Exception
unchecked exceptions(不受检查异常):即使不处理也可正常通过编译。
- 包括
RunTimeException(运行时异常)及其子类;日常开发中经常用到。
RunTimeException
即通常所说的异常。
NullPointerException(NPE):需进行 NPE 检查,使用 JDK8 的 Optional 类来防止 NPE 问题。可能出现 NPE 的有:- 返回类型为基本数据类型,return 包装数据类型的对象(为 null)时,自动拆箱(找不到对应的 int 类型)可能产生 NPE,如
public int getXxx() { return Integer 对象; };- 条件表达式/三目运算符在类型对齐时;
- 所有的 POJO 类属性必须使用包装数据类型(没有初值,提醒使用者必须显式地赋值,自己保证 NPE 检查和入库检查),所有的局部变量推荐使用基本数据类型。
- 数据库查询结果可能为 null;如,当某一列的值全是 NULL 时,
count(col) 的返回结果为 0,但 sum(col) 的返回结果为 NULL,解决:SELECT IF(ISNULL(SUM(col)), 0, SUM(col)) FROM table; - 集合里的元素即使 isNotEmpty,取出的数据元素也可能为 null;Map 集合类(
HashMap、CurrentHashMap、HashTable、TreeMap)的 Key/Value是否允许存储 null 值; - 远程调用返回对象时,一律要进行空指针判断;
- 对于 Session 中获取的数据;
- 级联(链式)调用
obj.getA().getB().getC(),一连串调用;
- 返回类型为基本数据类型,return 包装数据类型的对象(为 null)时,自动拆箱(找不到对应的 int 类型)可能产生 NPE,如
ArrayIndexOutOfBoundsException:数组下标越界;ArrayStoreException:向类型不兼容的数组元素赋值;ClassCastException:类型转换异常;MethodArgumentNotValidException:Hibenate Validator 验证框架@Valid参数验证失败;NumberFormateExceptionArithmeticException:算数错误;SecurityException:安全错误,如权限不够;UnsupportedOperationException:不支持的操作错误,如重复创建同一用户;RejectedExecutionException:线程池拒绝策略;
1 | |
Throwable 类的常用方法
void printStackTrace():在控制台上打印Throwable对象封装的异常信息;String getMessage():返回异常发生时的简要描述;String getLocalizedMessage():默认返回getMessage();若用Throwable的子类覆盖此方法,返回异常对象的本地化信息。ExceptionUtil.getMessage(e)
String toString():返回异常发生时的详细信息;ex.getCause():返回此异常的原因。当原因不存在或未知时,返回 null。
1 | |
try-catch-finally
try 块: 用于捕获异常。其后可接多个 catch 块;如果没有 catch 块,则必须跟一个 finally 块。
catch 块 :用于处理 try 捕获到的异常。
- JVM 在方法栈中查找能处理该类型异常的对象。捕捉异常并处理的代价远大于直接抛出。
throw 块:一般用在方法内部(出现异常的地方),由开发者定义,当程序语句出现问题后,创建异常对象并(立即主动)抛出异常(提交给 JVM)。
throws:一般用在方法声明上,代表可能会抛出的异常列表。
finally 块:无论是否捕获或处理异常,语句最终一定执行;当在 try 块或 catch 块中遇到 return 语句时,在方法返回前执行。常用于回收、释放资源。
- 以下情况不会执行
finally块,而是直接结束:- 当程序在进入try语句块前就出现异常时;finally 前 JVM 被终止运行;
- 当程序在try块中强制退出时,如用
System.exit(0); - 程序所在的线程死亡;
- 关闭 CPU;
- 其它情况下,try 块先执行,
- 当有异常发生,catch 和 finally 进行处理后程序就结束了;
- 当没有异常发生,在执行完 finally 中的代码后,后面代码会继续执行。
- 不要在 finally 语句块中使用
return:当 try 和 finally 语句中都有 return 语句时,finally 块中的会覆盖 try/catch 中的。
1 | |
try-with-resources
Java 7 之后,面对必须要关闭的资源,应优先使用 try-with-resources 而不是try-finally。
-
代码更简短、清晰,产生的异常对也更有用。
-
类似于
InputStream、OutputStream、Scanner、PrintWriter等资源调用close()方法来手动关闭。
1 | |
泛型
泛型(Generics)参数:即参数化类型:<数据类型>。编译器可对泛型参数进行检测,通过泛型参数**指定**传入的对象类型。
- 只是一个占位符,必须在传递类型后才能使用。常用
E,T,K,V,?(通配符)表示,用于对象具体类型不确定的情况。 - 泛型没有继承关系:虽然 BMW 和 BENZ 都继承了 Car,但
ArraryList<BMW>和ArraryList<BENZ>与ArraryList<Car>无关。
例如:
- 自定义接口通用返回结果
CommonResult<T>通过参数T可根据具体的返回类型、动态指定结果的数据类型; - 定义
Excel处理类ExcelUtil<T>用于动态指定Excel导出的数据类型; - 构建集合工具类(参考
Collections中的sort,binarySearch方法)。
使用方式
3种使用方式:
- 泛型类:实现泛型类时再传入真实数据类型;
- 泛型接口:
- 实现泛型接口,不指定类型;
- 实现泛型接口,指定类型;
- 泛型方法;
1 | |
反射机制
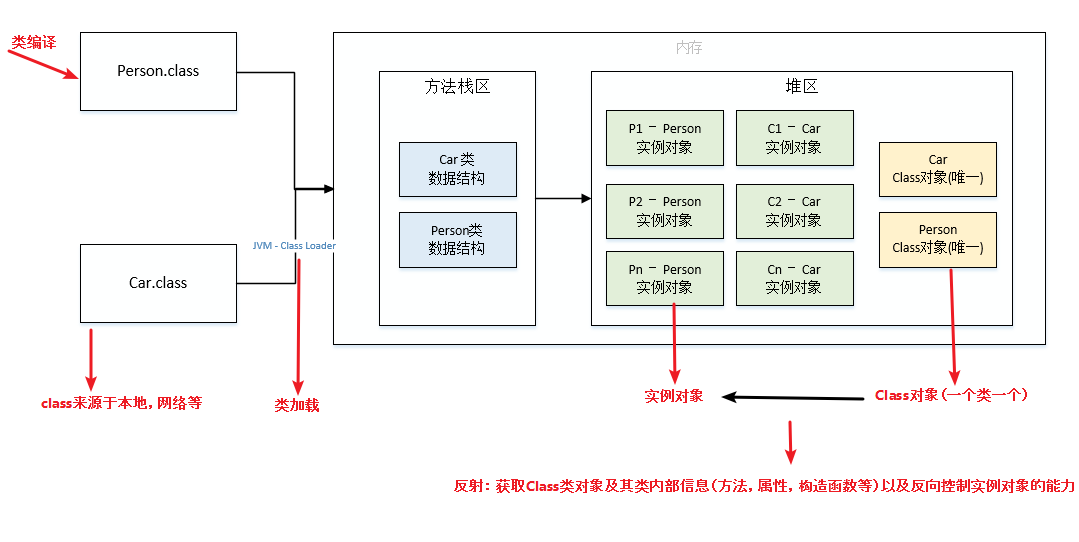
反射
反射:(在运行期/时)获取Class 类对象及其类内部详细信息(成员方法、属性、构造函数等)、及反向控制实例对象的能力。
-
将(类/接口的)
.class字节码文件加载进 JVM (的方法区)时,会(在堆中)创建一个对应的java.lang.Class对象,用来映射类中的各种成分。 - 这种动态获取类信息及调用对象方法的功能称为Java语言的反射机制。
- 反射是线程安全的。
应用场景
多用于框架的底层原理,是框架的灵魂。通过反射可在运行时分析类及执行类中方法,获取、调用任意一个类的所有属性和方法。
- Spring/Spring Boot、MyBatis 等框架中都大量使用反射机制,框架中动态代理的实现也依赖反射;
- 动态代理机制:JDK提供的(如
Proxy.newProxyInstance())没有实现类、但在运行期动态创建接口对象的方式。通过Proxy创建代理对象,然后将接口方法“代理”给InvocationHandler完成的。 - MyBatis 通过反射创建对象,同时用反射给对象的属性逐一赋值并返回。
<resultMap>元素。
- 动态代理机制:JDK提供的(如
- 注解的实现用到反射。
- 如,Spring 中通过
@Component注解声明一个类为 Spring Bean、 通过@Value注解就读取到配置文件中的值:基于反射分析类,获取到类/属性/方法/参数上的注解,之后就可做进一步的处理。
- 如,Spring 中通过
toString()里重写并打印类信息。
优缺点
-
优点 :代码更灵活;为各种框架提供开箱即用的功能提供便利;
-
缺点 :不安全。如,可无视(发生在编译时的)泛型参数的安全检查;性能稍差。
获取 Class 类对象
获取 Class 对象的方式有:
-
(一般不知道具体类),知道具体类的情况下:
类名.class。Class 对象不会进行初始化(不执行静态代码块和静态对象); -
实例对象.getClass(),继承自Object.getClass(); -
Class.forName("类的全限定名"); -
通过类加载器xxxClassLoader.loadClass(类路径?)。Class 对象不会进行初始化。1
2
3private static final Logger LOGGER = LoggerFactory.getLogger(UmsAdmin.class); ClassLoader.getSystemClassLoader().loadClass("cn.javaguide.User");
反射的使用 / 常用类基本操作
可通过以下类调用反射API(JavaGuide 反射的一些基本操作):
Class 类
Class 类:可获得(Class 对象所表示的)类的属性、方法,是一个 Java 中的泛型类型。
- 用于封装被加载到 JVM 中的类和接口的信息。
常用方法有:
Class<?> getClass():获取类引用;getName():获取全限定类名;getSimpleName():获取类名,用于toString()打印 POJOs 的类名;
newInstance():实例化;- getPackage()
Class getSuperclass():获取父类类型;- Class[] getInterfaces():获取当前类实现的所有接口;
获取构造器、字段和方法:后续再用 Construct 类、Filed 类、Method 类处理。
- Constructor<?>[] getConstructors()
Fileds[] getFileds()Field getField(String name):获取公有字段;getDeclaredFields:用于获取所有声明的字段,包括公有和私有字段;
- Method[] getMethods()
- Method getMethod(String name, Class<?>… parameterTypes)
Construct 类
Construct 类:获取(Class对象所表示的)类的构造方法,可在运行时动态创建对象。
Field 类
Field 类:获取(Class对象所表示的)类的成员变量,及对它的(运行时)动态修改权限(包含private)。
setAccessible(true):为了调用 private 方法而取消安全检查;String 类的定义;getName():返回字段名称,如"id";getType():返回字段类型,也是一个Class实例,如,String.class;int getModifiers():返回字段的修饰符,不同的bit表示不同的含义。
Method 类
Method 类:获取(Class对象所表示的)类的成员方法,可动态调用对象的方法(包含private)。
Object invoke(Object obj, Object... args):JVM 调用包装在当前 Method 对象obj 中的方法,并传入方法调用的参数 args。- 调用静态方法时传入的第一个参数为
null;
- 调用静态方法时传入的第一个参数为
getName():返回方法名称,如:"getScore";getReturnType():返回方法返回值类型,也是一个Class实例,如:String.class;getParameterTypes():返回方法的参数类型,是一个Class数组,如:{String.class, int.class};int getModifiers():返回方法的修饰符,不同的bit表示不同的含义。
代码示例
1 | |
执行流程及原理
- 用软引用 relectionData 缓存 class 信息,避免每次都重新从 JVM 获取带来的开销;
- 当找到需要的方法,会copy一份,而不是用原来的实例,从而保证数据隔离;
- 调度反射方法,最终是由 JVM 执行
invoke0()执行;
注解
Annotation (注解):是 Java5 开始引入的新特性,可看作是一种特殊的注释,本质是继承了 Annotation 特殊接口。
- 主要用于修饰类、方法、变量,提供某些信息供程序在编译或运行时使用。
注解解析方法
注解只有被解析后才会生效,常见的解析方法有两种:
- 编译期直接扫描:编译器在编译代码时,扫描对应的注解并处理。
- 如
@Override注解:编译器在编译时就会检测当前的方法是否重写了父类对应的方法。
- 如
- 运行期通过反射处理:框架中自带的注解(如 Spring 框架的
@Value、@Component)。
注解分类
JDK 内置注解:
-
由编译器使用的注解,作用在代码上。如:
@Override:检查该方法是否正确实现了覆写;@Deprecated:标记过时(已弃用)方法。如果使用该方法,会报编译警告;@SuppressWarnings:告诉编译器忽略此处代码产生的警告;
-
元注解:作用在其他注解上的注解,用于定义其它注解(
@interface类型的类)。-
@Target:标记注解作用在哪种成员上:1
2
3
4
5
6
7
8
9
10/** Class, interface (including annotation type), or enum declaration */ TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE, ANNOTATION_TYPE, PACKAGE, // since 1.8 TYPE_PARAMETER, TYPE_USE -
@Retention(RetentionPolicy.SOURCE):标识注解怎么保存:SOURCE:只在源代码中;CLASS:编入class文件中;RUNTIME:在运行时可通过反射访问。
-
@Documented:标记注解是否包含在用户文档中。 -
@Inherited:标记注解继承于哪个类(默认没有继承于任何父类)。
1
2
3
4@Target({ElementType.FIELD, ElementType.TYPE}) @Retention(RetentionPolicy.SOURCE) public @interface Setter { } -
-
从 Java 7 开始,额外添加了 3 个注解:
@SafeVarargs: 忽略任何使用参数为泛型变量的方法或构造函数调用产生的警告。@FunctionalInterface:Java 8 开始支持,标识匿名函数或函数式接口。@Repeatable:Java 8 开始支持,标识注解可在同一个声明上使用多次。
-
在程序运行期能读取的注解。在加载后一直存在于JVM中,最常用。如:
@PostConstruct标注的方法会在调用构造方法后自动被调用(这是 Java 代码读取该注解实现的功能,JVM 并不会识别该注解)。
I/O 和序列化
序列化
目的:持久化 Java 对象,将对象存储到文件系统、数据库、内存中,或通过网络传输对象;
- 序列化: 将对象(包括对象的类型信息、存储在对象中的数据及其类型)转换成二进制字节流的过程;
- 反序列化:在内存中新建对象。如果 JVM 在反序列化时找不到该类,则抛出一个
ClassNotFoundException异常。
整个过程都是 JVM 独立的:
- 即,在一个平台上序列化的对象可在另一个(完全不同的)平台上反序列化该对象。
序列化和反序列化,对应 OSI 七层协议模型中的表示层、属于 TCP/IP 四层模型中应用层的一部分:
- 主要就是对应用层的用户数据进行处理转换为二进制流。
常见应用场景
- 将内存中的对象存储到文件中时需进行序列化,将对象从文件中读取出来需进行反序列化。
- 比较常见,如用 Mybatis 框架编写持久层 insert 对象数据到数据库中时;
- 将对象存储到缓存数据库(如 Redis)时需用到序列化,将对象从缓存数据库中读取出来需反序列化;
- 对象在进行网络传输(如远程方法调用 RPC )之前需先被序列化,接收到序列化的对象之后进行反序列化。
- 用 Socket 套接字在网络中传送对象时,如用 RPC 协议进行网络通信时;
具体实现
常见序列化协议:
- 文本类序列化:可读性较好,但性能较差,一般不会选择;
JSON、XML- Jackson 序列化:见 Spring MVC 文档。
- 基于二进制的序列化协议:
- JDK 自带的序列化;
- Kryo:推荐;
- Protobuf
- hessian
JDK 自带序列化的实现:
几乎不直接用此方式,主要原因有:
- 不支持跨语言调用;
- 相比于其他序列化框架性能更差,序列化后的字节数组体积较大,导致传输成本加大。
- 用于序列化和反序列化的类必须实现
java.io.Serializable接口:- 用于实现 Java 类的序列化操作而提供的一个语义级别的接口。没有任何方法或字段,只是用于标识可序列化的语义。
- 实现了 Serializable 接口的类可被 ObjectOutputStream 转换为字节流,也可通过 ObjectInputStream 再将其解析为对象。
1 | |
trasient 关键字、@transient
作用:阻止实例中(用 trasient 修饰的)属性序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
对象中如果有属性不想被序列化,可以属性前添加关键字 transient、或使用 @transient 修饰。
- 一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
- 被transient关键字修饰的成员变量不能被序列化,(修饰的对象需实现 Serializable 接口,在反序列化后变量值将会被置成默认值);
- 只能修饰变量,而不能修饰方法和类、局部变量。
- 静态变量不管是否被transient修饰,均不能被序列化。
- 序列化保存的是对象状态,静态变量保存的是类状态,不属于任何对象,因此静态变量不能被序列化。
- 如果反序列化后类中 static 变量还有值,则为当前 JVM 中对应 static 变量的值。
serialVersionUID
serialVersionUID:适用于JAVA序列化机制。简单来说,通过判断类的serialVersionUID来验证版本一致。
- 显式地定义
serialVersionUID:在反序列化时,JVM 会把传来的字节流中的serialVersionUID与本地相应实体类的(serialVersionUID)进行比较,- 如果相同说明是一致的(认为是同一个类),可以进行反序列化,
- 否则会出现反序列化版本一致的异常,即是
InvalidCastException。
- 序列化类新增属性时,不要修改
serialVersionUID字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱,需修改。
1 | |
Java I/O 流
IO 即 Input/Output,输入和输出。
- 数据输入到计算机内存的过程即输入,反之输出到外部存储(如数据库,文件,远程主机)的过程即输出。
- 数据传输过程类似于水流,因此称为 IO 流。
IO 流在 Java 中分为输入流和输出流,而根据数据的处理方式又分为字节流和字符流。
Java IO 流的 4 个抽象类基类:
InputStream(字节输入流):用于从源头(通常是文件)读取数据(字节信息)到内存中;read()方法:返回输入流中下一个字节的数据。FileInputStream:常用的字节输入流对象,指定文件路径,可直接读取单字节数据,也可读取至字节数组中。通常会配合BufferedInputStream。BufferedInputStream(字节缓冲输入流):不是一个一个字节的读取,而是先将读取到的字节存放在缓存区,并从内部缓冲区中单独读取字节。BufferedInputStream内部维护了一个缓冲区,通过源码可知实际就是一个字节数组。- 大幅减少了 IO 次数,提高了读取效率。
-
OutputStream(字节输出流)BufferedOutputStream(字节缓冲输出流):缓冲流将数据加载至缓冲区,一次性读取/写入多个字节,从而避免频繁的 IO 操作,提高流的传输效率。
-
Reader(字符输入流):BufferedReader(字符缓冲输入流)
-
Writer(字符输出流):BufferedWriter(字符缓冲输出流)
ObjectInputStream 类
和
ObjectOutputStream类
public final Object writeObject() throws IOException方法:序列化一个对象,并发送到输出流;//?public final Object readObject() throws IOException, ClassNotFoundException方法:从流中取出下一个对象,并反序列化。- 返回值为Object,因此需转成合适的数据类型。
1 | |
Java I/O 中的设计模式
- 装饰器
- 适配器
- 工厂模式
- 观察者模式
I/O 模型
日常开发过程中接触最多的就是 磁盘 IO(读写文件) 和 网络 IO(网络请求和响应)。
I/O 模型:
- 同步阻塞 I/O:应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
BIO(Blocking I/O)
- 同步非阻塞 I/O
- I/O 多路复用
- Redis 单线程模型
- NIO (
Non-blocking/New I/O):支持面向缓冲,基于通道的 I/O 操作方法。 用于高负载、高并发的(网络)应用;- 见 RPC 框架文档。
- 信号驱动 I/O
- 异步 I/O
- AIO (
Asynchronous I/O)
- AIO (
Socket 网络编程
Spring MVC 中的 WebSocket
- 见 WebSocket 文档。
Stream 流
新增了 java.util.stream 包。
Stream(流)是一个(来自数据源的)元素队列并支持聚合操作。流是一种新的数据处理模型,可以对数据进行并行处理,提高程序的性能。
- 数据源:流的来源,可以是集合,数组,I/O channel, 产生器generator 等。
- 元素:是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 聚合操作:类似SQL语句一样的操作, 比如
filter, map, reduce, find, match, sorted等。
Stream 可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。
- 简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
- 只用简单的调用API函数即可,更方便。可以保证速度、和准确率。
- 尤其是在算法题中,For循环和数据结构的使用会让代码看着很乱。
特点:
- 不是数据结构,不会保存数据。
- 不会修改原来的数据源,会将操作后的数据保存到另外一个对象中。
- 惰性求值:流在中间处理过程中,只是对操作进行了记录,并不会立即执行,需要等到执行终止操作的时候才会进行实际的计算。
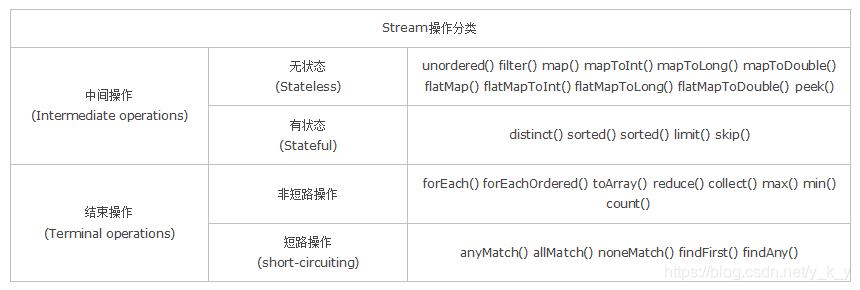
操作分类
参考:玩转 Java8 Stream 流,常用方法,详细用法大合集!
- 无状态: 指元素的处理不受之前元素的影响;
- 有状态: 指该操作只有拿到所有元素之后才能继续下去。
- 非短路操作: 指必须处理所有元素才能得到最终结果;
-
短路操作: 指遇到某些符合条件的元素就可以得到最终结果。如 A B,只要A为true,则无需判断B的结果。
创建流
在 Java 8 中,生成流的方法有:
- 使用
Collection下的Stream stream()、parallelStream()方法:为集合创建串行、并行流。 - 使用 Arrays 中的
Arrays.stream()方法:将数组转换成流。 - 使用 Stream 中的静态方法:
of()、iterate()、generate()。 - 使用
BufferedReader.lines()方法,将每行内容转成流。 - 使用
Pattern.splitAsStream()方法,将字符串分隔成流。
Collection 接口的 stream()
1 | |
Arrays.stream()
Array.Stream()返回的是一个元素序列,且支持顺序和并行的聚合操作。- 其实可以把它理解为包装类。
- 对于Int来说,元素序列类型为OptionalInt,包装类为Integer,它们在各自的领域各司其职,只不过Int类型和Integer类型可以自动转化。
- 所以在上面还需要调用getAsInt()函数来进行转化Int类型。
1 | |
Stream:of()、iterate()、generate()
1 | |
BufferedReader.lines()
1 | |
Pattern.splitAsStream()
1 | |
流的中间操作
无状态
无状态: 指元素的处理不受之前元素的影响;
filter()
用于通过设置的条件过滤出元素。过滤流中的某些元素。
1 | |
map() 映射
- map: 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
- flatMap: 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
map() 用法:将流中的元素转换为另外一个流中的元素,转换前后元素个数不变。
- 接收一个函数式接口参数,入参有一个T,返回一个Stream流。
- 在日常的开发工作中经常碰到,要处理list中数据的问题。
- 比如从数据库中查出了很多学生,在内存中找出这些学生中的所有姓名,或把名为“王五”的语文成绩暂时修改为“100”。
- 在java8中对集合可以进行流式操作(fluent style)使上面的处理更简洁。
1 | |
mapToInt()
peek()
peek:如同于map,能得到流中的每一个元素。
- 但map接收的是一个Function表达式,有返回值;
- 而peek接收的是Consumer表达式,没有返回值。
1 | |
有状态
有状态: 指该操作只有拿到所有元素之后才能继续下去。
1 | |
distinct
distinct:通过流中元素的 hashCode() 和 equals() 去除重复元素。
sorted() 排序
sorted():自然排序,流中元素需实现Compareable接口sorted(Comparator com):定制排序,自定义Comparator排序器
sorted 方法用于对流进行排序。
1 | |
limit()
limit 方法用于获取指定数量的流。 limit(n):获取n个元素。
1 | |
skip(n)
skip(n):跳过n元素,配合limit(n)可实现分页。
流的终止操作
非短路操作
非短路操作: 指必须处理所有元素才能得到最终结果;
forEach()
用来迭代流中的每个数据。
1 | |
toArray()
1 | |
reduce() 规约操作
Optional<T> reduce(BinaryOperator<T> accumulator):- 第一次执行时,accumulator函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素;
- 第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素;依次类推。
T reduce(T identity, BinaryOperator<T> accumulator):流程跟上面一样,只是第一次执行时,accumulator函数的第一个参数为identity,而第二个参数为流中的第一个元素。<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner):- 在串行流(stream)中,该方法跟第二个方法一样,即第三个参数combiner不会起作用。
- 在并行流(parallelStream)中,我们知道流被
fork join出多个线程进行执行,此时每个线程的执行流程就跟第二个方法reduce(identity,accumulator)一样,而第三个参数combiner函数,则是将每个线程的执行结果当成一个新的流,然后使用第一个方法reduce(accumulator)流程进行规约。
1 | |
collect() 收集
collect:接收一个Collector实例,将流中元素收集成另外一个数据结构。
Collector 接口
Collector<T, A, R> 是一个接口,有以下5个抽象方法:
-
Supplier<A> supplier():创建一个结果容器A -
BiConsumer<A, T> accumulator():消费型接口,第一个参数为容器A,第二个参数为流中元素T。 -
BinaryOperator<A> combiner():函数接口,该参数的作用跟上一个方法(reduce)中的combiner参数一样,将并行流中各个子进程的运行结果(accumulator函数操作后的容器A)进行合并。 -
Function<A, R> finisher():函数式接口,参数为:容器A,返回类型为:collect方法最终想要的结果R。 -
Set<Characteristics> characteristics():返回一个不可变的Set集合,用来表明该Collector的特征。有以下三个特征: -
CONCURRENT:表示此收集器支持并发。(官方文档还有其他描述,暂时没去探索,故不作过多翻译)UNORDERED:表示该收集操作不会保留流中元素原有的顺序。IDENTITY_FINISH:表示finisher参数只是标识而已,可忽略。
Collectors 工具库
Collector工具库:Collectors。Java8引入了流(Stream)处理,新类java.util.stream.Collectors。
实现了很多归约操作。
- 用于返回列表或字符串:
Collectors.toList():将流转换成集合Collectors.toSet()Collectors.toMap(Student::getName, Student::getAge)Collectors.joining()- 聚合操作:
Collectors.counting()Collectors.maxBy(Integer::compare)Collectors.summingInt(Student::getAge)Collectors.averagingDouble(Student::getAge)
Collectors.groupingBy(Student::getAge):分组Collectors.partitioningBy(v -> v.getAge() > 10):分区Collectors.reducing(Integer::sum):规约
1 | |
Collectors.toList()
Collectors.toList()方法用于将流转换为列表(List)。这个方法在处理数据过滤、映射等操作后,能方便地收集结果到列表中。
- 例如,通过filter筛选出大于2的数,然后使用
Collectors.toList(),可以得到一个新的只包含符合条件的数的列表。这是一个高效且灵活的编程方式。
1 | |
Collectors.toSet()
1 | |
max()/min()/count() 聚合
count:返回流中元素的总个数。max:返回流中元素最大值。min:返回流中元素最小值。
1 | |
summaryStatistics() 统计
产生统计结果的收集器。主要用于int、double、long等基本类型上,可以用来产生类似如下的统计结果。
1 | |
短路操作
| 短路操作: 指遇到某些符合条件的元素就可以得到最终结果。如 A | B,只要A为true,则无需判断B的结果。 |
1 | |
xxxMatch() 匹配
allMatch():接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回falsenoneMatch():接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回falseanyMatch():接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false
findFirst()/findAny()
findFirst:返回流中第一个元素findAny:返回流中的任意元素
get()
JDK1.8 新特性
接口
- interface 中的方法可用
default或static修饰,这样就可有方法体,实现类也不必重写此方法。
Lambda 表达式
用于:
- 简化、替代(函数式接口的)匿名内部类写法;
- 集合迭代;
- 方法的引用;
- 访问变量;
语法格式
1 | |
Stream 流
新增了 java.util.stream 包。
Stream(流)是一个来自数据源的元素队列并支持聚合操作。流是一种新的数据处理模型,可以对数据进行并行处理,提高程序的性能。
Optional
用于解决 NPE 问题。
Date-Time API
- 格式化;
- Java 8 前转换都需借助
SimpleDateFormat类,而Java 8 后只需LocalDate、LocalTime、LocalDateTime的of或parse方法; - 之前都对应
Date;现在 JDBC 时间类型和 Java8 时间类型对应关系是:Date—>LocalDate;Time—>LocalTime;Timestamp—>LocalDateTime。
- 引入
java.time.ZonedDateTime来表示带时区的时间,可看成是LocalDateTime + ZoneId。
常用类
Collections 类
详细方法见 Java 集合框架文档中。
1 | |
Object 类
类中的方法及作用
如果定义类时并未显式指定父类,则默认继承 java.lang.Object 类:
-
toString():默认返回(带包的)类全名@当前对象在堆内存的地址(类的名字实例的哈希码 16 进制字符串),通常重写来返回对象的内容;如"org.webtree.www.User@Hello"。 -
equals():默认比较 2 个对象的内存地址是否相等,String 类对该方法进行了重写,用于比较字符串的内容是否相等。1
2
3
4
5
6
7
8
9
10
11// 方法一: @Override public boolean equals(Object obj) { if (obj instanceof Student) { Student stu = (Student)obj; return this.name.equals(stu.name); // this.name 无判空 } else { return false; } } // 方法二:Lombok 插件自动生成 -
clone():用于创建并返回当前对象的一份拷贝。慎用,默认是浅拷贝,若想实现深拷贝需覆写 clone() 方法实现成员对象的深度遍历式拷贝。 -
finalize():实例被垃圾回收器回收时触发的操作;当 GC 准备好释放对象占用空间时,首先会调用 finalize(),并在下一次垃圾回收动作发生时真正回收对象占用的内存。
1 | |
Objects 类
1 | |
Character 类
1 | |
String 类
String类有11种构造方法:
String 类定义
String 是用 private final 修饰的字符数组保存,每次都创建新对象(多了会导致性能降低)。String 类是不可变类,一旦创建,其值不可改变,适用于不常改变长度的字符串,str.length()。
private修饰符:表示值不会被外部修改。其实可通过反射机制改变值。final:表示 char 数组的引用地址不可变。
二者配合可以保证用 String 类声明的对象的值不可变。
1 | |
运算符重载:Java 语言本身并不支持运算符重载,+ 和 += 是专门为 String 类重载过的运算符,也是 Java 中仅有的两个重载过的运算符。
String.intern() 是一个 native(本地)方法,作用是将指定的字符串对象的引用保存在字符串常量池中,可简单分为两种情况:如果字符串常量池中
- 保存了对应的字符串对象的引用,直接返回该引用。
- 没有保存的话,在常量池中创建一个指向该字符串对象的引用并返回。
创建字符串对象的方式
1 | |
String 类不可变的优缺点
一、好处:
-
使 JVM 可实现字符串常量池:复制 String 变量、new 同一字面量、不同的(字符串)变量指向相同的字面量,都是指向字符串常量池中(同一内存地址的)同一对象。字符串常量池的好处:
- 可重复使用字符串常量,避免每次都重新创建相同对象,节省内存。
- 不影响引用该对象的其他变量;如果字符串是可变的,当某个变量改变值时,其他指向该内存地址的变量的值也会改变,不符合常量池设计的初衷。
- 保证了字符串对象在多线程环境下是线程安全的。常用字符串来传递数据,如数据库的用户名密码、网络编程中的 IP 和端口。
- 因为字符串是不可变的,故其值不能被修改;
- 如果可变,则可通过改变引用地址指向的值去修改字符串的值,从而导致安全漏洞。
- 内存地址不变,而 hashcode 由内存地址间接得到,因此保证了 String 对象的
hashcode的唯一性:创建 String 时hashcode就被缓存了,不必每次重新计算,处理速度快,很适合作为 Map 的键。
二、缺点:每次修改 String 对象都会产生新对象,占用内存。如 String 对象的 + 拼接操作直接生成新常量,并把 String 对象引用指向新常量。
final String
字符常量 VS 字符串常量
-
形式:字符常量 char 是单引号引起的一个字符,属于基本类型变量;字符串常量 final String 是双引号引起的 0 或若干个字符,属于对象。二者可相互转换。
1
2
3
4
5
6
7
8
9// char 在 Java 中占两个字节 char ch = ‘a’; String str = “hello”; // char 和 String 相互转换 char ch = str.charAt(0); str = Character.toString(‘c’); str = new Character(‘c’).toString(); str = “” + ‘c’; -
含义:字符常量相当于一个整型值(ASCII 值),可进行表达式运算;字符串常量代表(该字符串在内存中存放位置的)地址值。
-
占内存大小:字符常量只占 2 个字节;字符串常量取决于长度。
String VS final String
- String str 为变量,虽然 String 类被 final 修饰,但 str 仍为变量;
- final String str 为编译期常量;
- == 比较引用的地址
1 | |
StringBuilder、StringBuffer
Java 提供了两个可变字符串类 StringBuilder 和 StringBuffer。
- 实际上,二者功能基本相似,方法也差不多。都是对原对象操作,都用无 final 修饰的字符数组保存。对象创建后,仍可修改值。
- 不同的是,
StringBuffer是线程安全的,方法都是synchronized修饰的,适用于多线程在字符串缓冲区中操作大量数据。用于多线程使用共享变量的情景。 - 而
StringBuilder则没有实现线程安全功能、非线程安全的,所以性能略高。适用于单线程在字符串缓冲区中操作大量数据。
因此在通常情况下,如果需要创建一个内容可变的字符串对象,则应该优先考虑使用 StringBuilder 类。
拼接字符串
StringBuffer 就是为了解决大量拼接字符串时产生很多临时对象问题而提供的一个类。它提供了 append 和 add 方法,可以将字符串添加到已有序列的末尾或指定位置。本质是一个线程安全的可修改的字符序列。
在很多情况下字符串拼接操作不需要线程安全,所以可以选择 StringBuilder。
- 通过
+拼接String对象,实际上是通过创建StringBuilder调用append()方法实现的,最后调用toString()得到一个新String对象 。 StringBuilder重载了toString(),在调用该类对象时自动返回一个字符串,用System.out.println(对象名)可打印出来。- 在循环内用
+拼接String对象,会导致创建过多的StringBuilder临时对象,造成内存资源浪费。可直接使用StringBuilder调用append()方法代替。
1 | |
参考:
常用方法
获判转替合,货盘转提盒
获取
int length():字符数;-
char charAt(int index):返回指定索引处的char;- 当访问不存在的下标时会发生
StringIndexOutOfBoundsException(下标越界异常);
- 当访问不存在的下标时会发生
int indexOf(**int** ch, [int fromIndex]):从指定位置开始,获取 ch 第一次出现的索引;未找到 ch 则返回 -1;-
int indexOf(**String** str, [int fromIndex]) -
lastIndexOf():同 indexOf;
-
String substring(begin, [end]):切片,截取指定位置[begin,end)的新子串。-
String[] split(String regex, [int limit]):根据正则匹配切割/拆分,需检查最后一个分隔符后有无内容,否则长度不及预期、会有抛出IndexOutOfBoundsException的风险。- regex:正则表达式分隔符。
- limit:分割份数。
1 | |
判断
boolean isEmpty(): 是否有内容。原理是判断字符串长度是否为0;boolean equals(str):判断字符串内容是否相同。重写了Object类中的equals(),只判断字符串内容是否相同;需对当前字符串判空;boolean equalsIgnoreCase():忽略大小写,判断内容是否相同;
boolean contains(str): 是否包含子串;- 同:
if (str.indexOf(str) != -1),区别:后者可获取子串出现的位置。
- 同:
boolean startsWith(String prefix):是否以指定前缀开头;boolean endsWith(String suffix);
int compareTo(str):比较两字符串的字典顺序,基于字符的 Unicode 值。相等返回 0;小于str参数,返回负数。
转换
char[] toCharArray():将字符串转成字符数组,常用于遍历for(char ch : str.toCharArray()){}byte[] getBytes():将字符串转成字节数组;String(byte[]):将字节数组转成字符串;
String toUpperCase():将字符串全部转成大写;String toLowerCase()
static String String.valueOf(int/double): 将基本数据类型 int/double 转成字符串;自动装箱。
替换和合并
操作都不是在原有的字符串对象上进行的,而是生成了新的 String 对象,然后将原 String 的变量引用指向新对象。
String replace(char old, char new):如果被替换的字符不存在,则返回原串;String replace(" ",""):消除字符串的所有空格;String trim():删除字符串的头尾空白符;
String replaceAll(String regex, String replaceStr):用replaceStr替换所有正则匹配到的子串。String replaceFirst(String regex, String replaceStr):只替换匹配的第一个子串。
String concat(String str): 将 str 拼接到结尾,不能拼接其他类型,二者都不能为 null,否则运行时会报空指针异常 NPE(编译时不报错)。+:可拼接字符、数字、字符串等数据类型;
String.join(String ",", List<String> wordList):合并 List,并插入逗号;
Math 类
abs()ceil():取上限floor()pow(2, 3)round(4.9999)
Date / LocalDateTime 类
计算机表示的时间是以整数表示的时间戳存储的,即 Epoch Time,Java使用long型来表示以毫秒为单位的时间戳,通过System.currentTimeMillis()获取当前时间戳。
Java标准库有两套处理日期和时间的API:
- 旧的定义:主要包括
Date、Calendar和TimeZone这几个类。位于在java.util包里面 - 新的 API:主要包括
LocalDateTime、ZonedDateTime、ZoneId等。是在Java 8引入的,定义在java.time这个包里面。
为什么会有新旧两套API呢?
- 因为历史遗留原因,旧的API存在很多问题,所以引入了新的API。
- 不能转换时区
- 很难对日期和时间进行加减
- 那么能不能跳过旧的API直接用新的API呢?如果涉及到遗留代码就不行,因为很多遗留代码仍然使用旧的API,所以目前仍然需要对旧的API有一定了解,很多时候还需要在新旧两种对象之间进行转换。
Date
java.util.Date是用于表示一个日期和时间的对象.
- 注意与
java.sql.Date区分,后者用在数据库中。 - 如果观察
Date的源码,可以发现它实际上存储了一个long类型的以毫秒表示的时间戳:
基本用法:
1 | |
注意:
getYear()返回的年份必须加上1900,getMonth()返回的月份是0~11分别表示``1~12`月,所以要加1,getDate()返回的日期范围是1~31,又不能加1。
打印本地时区表示的日期和时间时,不同的计算机可能会有不同的结果。如果想要针对用户的偏好精确地控制日期和时间的格式,就可以使用SimpleDateFormat对一个Date进行转换。
- Java的格式化预定义了许多不同的格式,以
MMM和E为例。 - 可以从JDK文档查看详细的格式说明。一般来说,字母越长,输出越长。
用预定义的字符串表示格式化:
- yyyy:年
- MM:月
M:输出9MM:输出09MMM:输出SepMMMM:输出September
- dd: 日
- HH: 小时
- mm: 分钟
- ss: 秒
Date对象有几个严重的问题:
- 不能转换时区,除了
toGMTString()可以按GMT+0:00输出外,Date总是以当前计算机系统的默认时区为基础进行输出。 - 此外,也很难对日期和时间进行加减,计算两个日期相差多少天,计算某个月第一个星期一的日期等。
Calendar
Calendar可以用于获取并设置年、月、日、时、分、秒,和Date比,主要多了一个可以做简单的日期和时间运算的功能。
基本用法:
1 | |
注意到Calendar获取年月日这些信息变成了get(int field),
- 返回的年份不必转换,
- 返回的月份仍然要加1,
- 返回的星期要特别注意,
1~7分别表示周日,周一,……,周六。
Calendar只有一种方式获取,即Calendar.getInstance(),而且一获取到就是当前时间。如果想给它设置成特定的一个日期和时间,就必须先清除所有字段:
1 | |
利用Calendar.getTime()可以将一个Calendar对象转换成Date对象,然后就可以用SimpleDateFormat进行格式化了。
TimeZone
与 Calendar和Date相比,提供了时区转换的功能。时区用TimeZone对象表示:
1 | |
时区的唯一标识是以字符串表示的ID,获取指定TimeZone对象也是以这个ID为参数获取,GMT+09:00、Asia/Shanghai都是有效的时区ID。
- 要列出系统支持的所有ID,请使用
TimeZone.getAvailableIDs()。
有了时区,就可以对指定时间进行转换。例如,下面的例子演示了如何将北京时间2019-11-20 8:15:00转换为纽约时间:
1 | |
可见,利用Calendar进行时区转换的步骤是:
- 清除所有字段;
- 设定指定时区;
- 设定日期和时间;
- 创建
SimpleDateFormat并设定目标时区; - 格式化获取的
Date对象(注意Date对象无时区信息,时区信息存储在SimpleDateFormat中)。
因此,本质上时区转换只能通过SimpleDateFormat在显示的时候完成。
Calendar也可以对日期和时间进行简单的加减:
1 | |
java.time
从 Java 8开始,java.time包提供了新的日期和时间API
其中,本地日期和时间 LocalDate、LocalTime、LocalDateTime是新API里的基础对象,绝大多数操作都是围绕这几个对象来进行的:三者都是没有时区、不可变、并且线程安全的
- LocalDate : 只含年月日的日期对象
- LocalTime :只含时分秒的时间对象
- LocalDateTime : 同时含有年月日、时分秒的日期对象
以及一套新的用于取代SimpleDateFormat的格式化类型DateTimeFormatter。
SimpleDateFormat:是线程不安全的类,一般不定义为 static 变量。如果定义为 static,必须加锁,或用 DateUtils 工具类。
不同的时区,在同一时刻,本地时间是不同的。
新时间日期API常用、重要对象介绍:
ZonedDateTime:带时区的日期和时间ZoneId,ZoneOffset: 时区ID,用来确定Instant和LocalDateTime互相转换的规则Instant: 时刻,用来表示时间线上的一个点(瞬时)Clock: 用于访问当前时刻、日期、时间,用到时区Duration: 时间间隔,用秒和纳秒表示时间的数量(长短),用于计算两个日期的“时间”间隔Period: 用于计算两个“日期”间隔
改变及原因
为什么需要 LocalDate、LocalTime、LocalDateTime
- Date如果不格式化,打印出的日期可读性差。
Tue Sep 10 09:34:04 CST 2019 - 使用SimpleDateFormat对时间进行格式化,是线程不安全的。
其它改变:
- 和旧的API相比,新API严格区分了时刻、本地日期、本地时间和带时区的日期时间,并且,对日期和时间进行运算更加方便。
- 此外,新API修正了旧API不合理的常量设计:
- Month的范围用1~12表示1月到12月;
- Week的范围用1~7表示周一到周日。
- 最后,新API的类型几乎全部是不变类型(和String类似),可以放心使用不必担心被修改。
不可变对象:
LocalDate、LocalTime、LocalDateTime、Instant为不可变对象,修改这些对象对象会返回一个副本。
- 增加、减少年数、月数、天数等 以LocalDateTime为例。
LocalDate
LocalDate是日期处理类,具体API如下:
1 | |
LocalTime
LocalTime是时间处理类,具体API如下:
1 | |
LocalDateTime
LocalDateTime可以设置年月日、时分秒,相当于LocalDate + LocalTime
1 | |
Instant
如果只是为了获取秒数或者毫秒数,使用System.currentTimeMillis()来得更为方便
1 | |
Duration
- 用于表示时间间隔或持续时间。主要用于计算两个时间点之间的差异,或者表示一段特定的时间长度。
- 可以精确到纳秒级别。它主要用于处理基于时间的量(小时、分钟、秒和纳秒),而不涉及日期或时区的概念。
1 | |
1. 获取时间值
1 | |
2. 时间运算
1 | |
3. 比较操作
1 | |
4. 其他实用方法
1 | |
hutool
见 SSM 框架、SpringMVC 文档。
BigInteger 类
64 位 long 整型是最大的整数类型,超过这个范围就会有数值溢出的风险;
1 | |
BigInteger 内部使用 int[] 数组来存储任意大小的整形数据。
1 | |
BigDecimal 类
作用:为了避免精度丢失,可用 Big'Decimal 来进行浮点数间的运算和比较大小;
浮点数精度陷阱
二进制无法精确表示浮点数:由于计算机(用尾数 + 阶码的编码方式)保存浮点数,二进制尾数宽度有限,无限循环的小数存储在计算机时,只能被截断;计算机内存放的值与实际值存在误差,导致浮点数精度陷阱。
- 在Java中float的精度为 7~ 8位有效数字,double精度为:16~17位有效数字
- float和double只能用来做科学计算或者是工程计算,存在精度丢失问题,
- 而涉及到较大数据,对精度有严格要求的计算中
BigDecimal是首选,比如金融、银行业务、涉及到货币的业务上的计算。 - 构造函数:
- String 构造方法是完全可预知的;
- 参数类型为double的构造方法的结果有一定的不可预知性,如果传入的参数必须是double类型时,可以通过
Double.toString(double b)方法转换成字符串传入,或者直接使用BigDecimal.valueOf(double b)来进行接收处理。
1 | |
因此,浮点数间的等值判断,
- 基本数据类型不能用
==来比较; - 包装数据类型不能用 equals 来判断。
1 | |
解决
-
指定一个误差范围,两个浮点数的差值在此范围内,则认为是相等的。缺点:仍有误差,只是误差较小。
1
2
3
4float diff = 1e-6F; if (Math.abs(a - b) < diff) { System.out.println(”true“); } -
用
BigDecimal类来保存值,再进行浮点数的运算操作。推荐创建BigDecimal对象的方式:BigDecimal(String val)构造方法;BigDecimal.valueOf(double val)静态方法:内部其实执行了 Double 的 toString,按 double 实际能表达的精度对尾数进行截断;BigDecimal(double):存在精度损失风险,在精确计算或值比较的场景中可能会导致业务逻辑异常。
1 | |
常见方法
加减乘除
1 | |
其他方法
1 | |
舍入模式
舍入模式(Rounding Mode):是BigDecimal类中的静态变量,包括了八种常见舍入规则,比如四舍五入法、银行家舍入法等。
ROUND_UP:正数向上取整,负数向下取整。向远离零的方向舍入。舍弃非零部分,并将非零舍弃部分相邻的一位数字加一ROUND_DOWN:向接近零的方向舍入。舍弃非零部分,同时不会非零舍弃部分相邻的一位数字加一,采取截取行为。ROUND_CEILING:正负均向上取整。取右边最近的整数,向正无穷的方向舍入。如果为正数,舍入结果同ROUND_UP一致;如果为负数,舍入结果同ROUND_DOWN一致。注意:此模式不会减少数值大小。ROUND_FLOOR:取左边最近的正数,向负无穷的方向舍入。如果为正数,舍入结果同ROUND_DOWN一致;如果为负数,舍入结果同ROUND_UP一致。注意:此模式不会增加数值大小。ROUND_HALF_UP:四舍五入。向“最接近”的数字舍入。负数先取绝对值再四舍五入再负数。ROUND_HALF_DOWN:五舍六入。向“最接近”的数字舍入。负数先取绝对值再五舍六入再负数。ROUND_HALF_EVEN:银行家舍入法。向离零最近的方向舍入,如果两个方向离零的距离相等,则选择偶数方向。在重复进行一系列计算时,此舍入模式可以将累加错误减到最小。- 四舍六入:
- 被舍位为5时两种情况:
- 五后非零:如果5后面有非零数字,则无论前面的数字为何,都应进位。
90.501 ≈ 91%、90.51 ≈ 91% - 如果5后面没有数字(或都是零),则需要查看5前面的数字:
- 五后零前偶:如果5前面的数字是偶数,则舍去5。
90.50 ≈ 90% - 五后零前奇:如果5前面的数字是奇数,则进位。
9.50 ≈ 10%
- 五后零前偶:如果5前面的数字是偶数,则舍去5。
- 五后非零:如果5后面有非零数字,则无论前面的数字为何,都应进位。
源码定义:- 如果舍弃部分左边的数字奇数,则舍入行为与
ROUND_HALF_UP相同,四舍五入; - 如果为偶数,则舍入行为与
ROUND_HALF_DOWN相同,五舍六入。 - 被舍位为5时两种情况,如果前一位为奇数,则入位,否则舍去。
- 如果舍弃部分左边的数字奇数,则舍入行为与
ROUND_UNNECESSARY:断言请求的操作具有精确的结果,因此不需要舍入。如果对获得精确结果的操作指定此舍入模式,则抛出ArithmeticException。
枚举类
用于信息标志和信息分类,元素为常量对象。
多例模式
继承Enum类
1 | |
正则表达式 Pattern 类
适合做校验
1 | |
System 类
- exit()
- cuurentTimeMilis()
- copyArray()基本不用