摘要:为了保证服务读写效率以及高可用性,通过读写分离、冷热分离解决数据库读并发的问题。
目录
[TOC]
数据库架构优化
为了保证服务读写效率以及高可用性,通过读写分离、冷热分离解决数据库读并发的问题,
随着业务量增长,单表的数据量达到性能瓶颈之后,通过分库分表(对数据库表进行水平拆分和垂直拆分)解决数据库存储压力的问题。
- 具体如何进行合理的拆分,以及技术选型,这些和项目现有的表结构设计是息息相关的,要考虑后续的可拓展性,不能短期拆了一时爽,
- 后续业务量增暴涨之后,服务器的性能不足以维持数据库的性能时,这时候要拆分服务器部署了。
如:
- 读写分离:主要是为了将数据库的读操作和写操作分散到不同的数据库节点上。部署多台数据库,主服务器负责写,从服务器负责读,通常一主多从。主从数据库间(通过主从复制)进行数据同步。需要尽量避免主从延迟。
- 分库分表:
- 分库:将数据库中的数据分散到不同的数据库上。
- 分表:对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。常见的分片算法。
- 引入分库分表之后,需要系统解决事务、分布式 id、无法 join 操作的问题。
- 冷热分离、使用缓存:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据。使用缓存存储热点数据。
常见中间件
Sharding-Sphere(分库分表的首选):是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。- 功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理、影子库、数据加密和脱敏等功能。
- 社区强大,已经进入 Apache 孵化。是当当捐入 Apache 的,目前主要由京东的一些巨佬维护。
- 在京东、当当等大型互联网公司落地使用,并且已经提供的有 100+ 企业的成功案例。
- 子项目
sharding-jdbc:推荐首选方案,是一款轻量级Java框架,以jar包形式提供服务,不需做额外运维,且兼容性很好。
MyCAT:基于 CobarTSharding(蘑菇街)Cobar(阿里巴巴)
读写分离
读写分离:主要是为了将数据库的读操作和写操作分散到不同的数据库节点上。部署多台数据库(集群),主数据库负责写,从数据库负责读,通常一主多从。主从数据库间(通过主从复制)进行数据同步。需要尽量避免主从延迟。
- 读写分离基于主从复制,MySQL 主从复制依赖于
binlog。 - 优点:
- 可大幅提高读性能,小幅提高写的性能。
- 提高服务器的负载、并发能力,可以根据读请求的规模自由增加或者减少从库的数量。
- 数据备份,快速恢复。
- 用途:因此更适合单机并发读、写少读多请求较多的场景。如商品数据库。
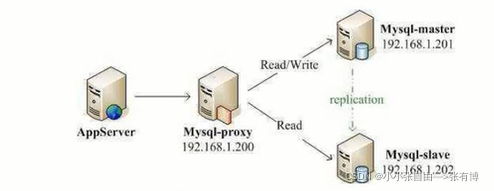
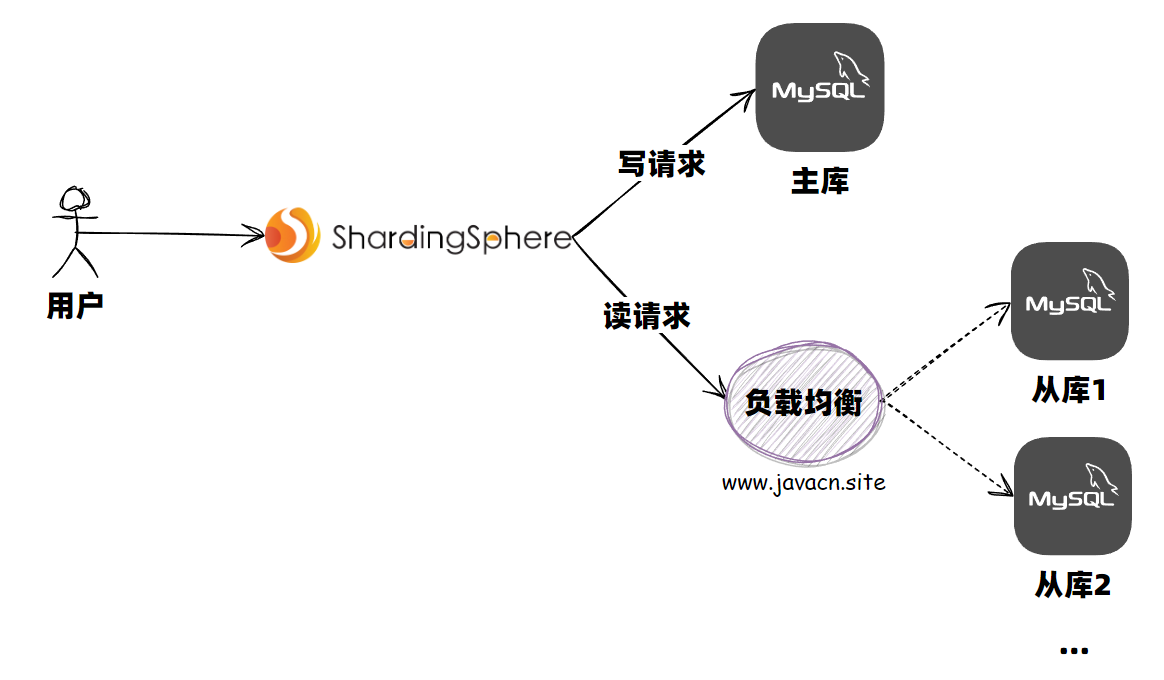
常用实现方式
- 代理方式:代理层负责分离读写请求,再路由到对应的数据库中。提供类似功能的中间件有 MySQL Router(官方)、Atlas(基于 MySQL Proxy)、Maxscale、MyCat。
- SDK 组件方式:引入第三方组件来帮助读写请求,推荐用
sharding-jdbc。
主从复制原理
MySQL 的主从复制
MySQL 主从复制依赖于 binlog 日志文件 。
- MySQL binlog(binary log 二进制日志文件) :主要记录了 MySQL 数据库中数据的所有变化(数据库执行的所有 DDL 和 DML 语句)。
- 因此,根据主库的 binlog 日志就能够将主库的数据同步到从库中。
主从复制的具体过程:
- 主库将数据库中数据的变化(用 DML 命令)写入到 binlog(Binary Log);
- 从库连接主库;
- 从库创建一个 I/O 线程向主库请求更新的 binlog;
- 主库创建一个 binlog dump 线程来(读取数据库事件)发送 binlog ,从库中的 I/O 线程负责接收;
- 从库的 I/O 线程将接收的 binlog 写入到 relay log 中。
- 从库的 SQL 线程读取 relay log 同步数据到本地(即再执行一遍 SQL )。
当然,除了主从复制之外,binlog 还能帮助实现数据恢复。
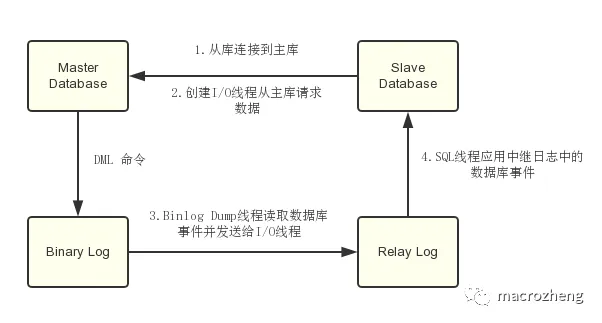
关于MySql的主从复制的实线可以参考:MySql主从复制,从原理到实践!
Redis 的主从复制
分布式缓存组件 Redis 也是通过主从复制实现的读写分离。
应用场景:电子商务网站上的商品,一般都是一次上传,无数次浏览的,也就是”多读少写”。
实现原理:
一个Redis服务可以有多个该服务的复制品,这个Redis服务称为 Master 主库,其它复制称为 Slaves 从库。主库只负责写数据,每次有数据更新都将更新的数据同步到它所有的从库,而从库只负责读数据。
主从(同步)延迟
主从同步延迟:主库和从库的数据存在延迟。
- 比如写完主库之后,主库的数据同步到从库需要时间,这个时间差就导致了主库和从库的数据不一致的问题。
如何避免主从延迟?
- 强制将读请求路由到主库处理;虽然会增加主库的压力,但是,实现起来比较简单。如
Sharding-JDBC。 - 延迟读取:对于一些对数据比较敏感的场景,可以在完成写请求之后,避免立即进行其它请求。
- 比如支付成功之后,跳转到一个支付成功的页面,当点击返回之后才返回自己的账户。
- 方便,这样设计业务流程就会好很多。
Gaea
传统的MySql读写分离方案是通过在代码中根据SQL语句的类型动态切换数据源来实现的。
Gaea是小米中国区电商研发部研发的,基于MySql协议的数据库中间件,目前在小米商城大陆和海外得到广泛使用,包括订单、社区、活动等多个业务。
- Gaea支持分库分表、SQL路由、自动读写分离等基本特性,其中分库分表方案兼容了mycat和kingshard两个项目的路由方式。
使用Gaea需要依赖MySql的主从复制环境。
读写分离测试思路
- 首先我们关闭从实例的主从复制,然后通过Gaea代理来操作数据库,插入一条数据,如果主实例中有这条数据而从实例中没有,说明写操作是走的主库。
- 然后再通过Gaea代理查询该表数据,如果没有这条数据,表示读操作走的是从库,证明读写分离成功。
分库分表
通过读写分离、冷热分离解决数据库读并发的问题,通过分库分表解决数据库存储压力的问题。
分库分表:按照业务划分数据库、按照规则拆分表到不同数据库,垂直拆分列、水平拆分行。
- 用于解决由于库、表数据量过大导致数据库性能持续下降的问题。
定义、常用方法
分库:将数据库中的数据分散到不同的数据库上。
- 垂直分库:把单一数据库按照业务进行划分。不同的业务使用不同的数据库,进而将一个数据库的压力分担到多个数据库。如:将数据库中的用户表、订单表和商品表分别单独拆分为用户数据库、订单数据库和商品数据库。
- 水平分库:把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上。解决了单表的存储和性能瓶颈问题。如:订单表数据量太大,对订单表进行了水平切分,将切分后的 2 张订单表分别放在两个不同的数据库。
分表:对单表的数据进行拆分。可以避免单表数据量过大对性能造成影响。
- 垂直分表:是对数据表列的拆分,把一张列比较多的表(一些列单独抽出来)拆分为多张表。如:可以将用户信息表中的作为一个表。(根据范式)
- 水平分表:是对数据表行的拆分,把一张行比较多的表(一些行单独抽出来)拆分为多张表。
- 为了提升性能,通常会选择将水平分表后的多张表放在不同的数据库中。即,水平分表通常和水平分库同时出现。
应用场景
- 单表的数据达到千万级别以上,数据库读写速度较慢(分表)。
- 数据库中的数据占用的空间越来越大,备份时间越来越长(分库)。
- 应用的并发量太大(分库)。
不过,分库分表的成本太高,如非必要尽量不要采用。
而且,并不一定是单表千万级数据量就要分表,毕竟每张表包含的字段不同,它们在不错的性能下能够存放的数据量也不同,还是要具体情况具体分析。
为什么要分库分表:
- 这个问题要结合读写分离、分区表来综合回答;
- 更进一步则要说清在具体的业务场景下,应该分库还是分表,还是说都要;
- 高端点则要将分库分表和其它中间件进行一个横向比较,站在一个集群模式的角度去讨论这个问题
设计原理
分库分表中间件的设计原理、步骤:
- 改写 SQL:给出一个逻辑 SQL 和相应的分库分表规则,你应该能够说清楚它的目标库和目标表
- 改写 SQL 的目标是生成物理/目标 SQL。主要受到两方面的影响:
- 查询本身
- 分库分表规则
- 举个典型例子来说,
SELECT * FROM user_tab WHERE id < 10000这条语句:- 如果是哈希分库分表,那么大概率是广播,即将查询发到全部表上
- 如果是范围分表,那么就可以根据范围来计算出准确的目标表
- 而如果是
SELECT avg(age) FROM user_tab,那么不管是范围还是哈希分库分表,都要改写为SELECT count(id), sum(age) FROM user_tab,然后在处理结果的时候根据 count 和 sum 来求平均值。
- 改写 SQL 的目标是生成物理/目标 SQL。主要受到两方面的影响:
- 执行 SQL:重点要考虑
- 目标 SQL 能不能并发执行
- 修改数据类的查询,例如说 INSERT、UPDATE、DELETE 之类的语句,如果目标 SQL 有多个,那么如果出现部分失败的问题该怎么解决
- 事务怎么处理
- 处理结果集:这个过程和前面改写 SQL 是很密切相关的,要考虑
- 排序和分页
- 聚合函数
实际中如何分库分表
- 实际中如何分库分表:
- 怎么挑选分库分表的键
- 主键怎么生成:不同策略的优缺点和潜在问题
- 从单裤单表开始分库分表,要怎么做
- 怎么计算分库分表应该要分多少库、多少表
- 如果中途发现分库分表需要扩容,怎么扩容:
- 怎么做数据迁移
- 怎么做数据校验
- 怎么切换流量
- 怎么做好回滚:即万一中间任何一个步骤出问题,能不能回滚,怎么回滚
- 分库分表的性能问题
- 排序查询性能问题以及优化方案
- 分页查询性能问题以及优化方案
- 非典型查询,是指不符合分库分表初衷的查询。例如在订单表中,典型的分库分表方案是使用买家 ID,那么如果卖家要查询自己卖了多少单,就很难查询
常见的分片算法
分片算法:主要解决了数据被水平分片(拆行)之后,数据该放在哪个表的问题。
常见的分片算法有:
- 哈希分片:求指定分片键的哈希,根据哈希值确定数据应被放在哪个表中。
- 可以使每个表的数据分布相对均匀,但对动态伸缩(例如新增一个表或者库)不友好。
- 比较适合随机读写的场景,不太适合经常需要范围查询的场景。
- 范围分片:按照特定的范围区间(比如时间区间、ID 区间)来分配数据。
- 比如 将
id为1~299999的记录分到第一个表,300000~599999的分到第二个表。 - 范围分片适合需要经常进行范围查找且数据分布均匀的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
- 比如 将
- 映射表分片:使用一个单独的映射表来存储分片键和分片位置的对应关系。
- 可以支持任何类型的分片算法,如哈希分片、范围分片等。可以灵活地调整分片规则,不需要修改应用程序代码或重新分布数据。
- 不过,需要维护额外的表,还增加了查询的开销和复杂度。
- 一致性哈希分片:将哈希空间组织成一个哈希环,将分片键和节点(数据库或表)都映射到这个环上,根据顺时针的规则确定数据或请求应该分配到哪个节点上。解决了传统哈希对动态伸缩不友好的问题。另外,见负载均衡算法中的一致性哈希法。
- 地理位置分片:根据地理位置(如城市、地域)来分配数据。
- 融合算法分片:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
- ……
分片键如何选择?
分片键(Sharding Key):是数据分片的关键字段。分片键的选择非常重要,它关系着数据的分布和查询效率。
一般来说,分片键应该具备以下特点:
- 具有共性: 能够覆盖绝大多数的查询场景,尽量减少单次查询所涉及的分片数量,降低数据库压力;
- 具有离散性:能够将数据均匀地分散到各个分片上,避免数据倾斜和热点问题;
- 具有稳定性:分片键的值不会发生变化,避免数据迁移和一致性问题;
- 具有扩展性:能够支持分片的动态增加和减少,避免数据重新分片的开销。
实际项目中,分片键很难满足上面提到的所有特点,需要权衡一下。
并且,分片键可以是表中多个字段的组合,例如取用户 ID 后四位作为订单 ID 后缀。
带来的问题
同一个数据库中的表分布在了不同的数据库中,可能会带来的问题:
- join 操作:无法使用 join 操作,导致需要手动进行数据的封装。
- 比如,在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。
- 不过,很多大厂的资深 DBA 都是建议尽量不要使用 join 操作。因为 join 的效率低,并且会对分库分表造成影响。对于需要用到 join 操作的地方,可以采用多次查询业务层进行数据组装的方法。不过,需要考虑业务上多次查询的事务性的容忍度。
- 事务问题:如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足要求了。需要引入分布式事务。
另外,可能会带来的问题:
- 分布式 id:分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键无法生成全局唯一主键。需要引入分布式 ID。
- 跨库聚合查询问题:分库分表会导致常规聚合查询操作,如
group by,order by等变得异常复杂。- 因为这些操作需要在多个分片上进行数据汇总和排序。为了实现这些操作,需要编写复杂的业务代码,或者使用中间件来协调分片间的通信和数据传输。
- 这样会增加开发和维护的成本,以及影响查询的性能和可扩展性。
分布式 ID
分布式 ID 是分布式系统下的 ID。
- 用于解决分库分表带来的问题。
- 如,分库后, 数据遍布在不同服务器上的数据库,为不同的数据节点生成全局唯一自增主键。
需满足:
- 全局唯一;
- 高性能: 生成速度快,对本地资源消耗小。
- 高可用(Availa’bility):生成分布式 ID 的服务要保证可用性无限接近于 100%。
- 方便易用:拿来即用,使用方便,快速接入。
- 安全:不包含敏感信息。
- 有序递增:可提升数据库写入速度,可能会直接通过 ID 来进行排序。
- 有具体的业务含义:让定位问题及开发更透明化(通过 ID 就能确定是哪个业务)。
- 独立部署:单独有一个发号器服务,专门用来生成分布式 ID。
常见解决方案:
- 数据库主键自增;
- 数据库号段模式;
- NoSQL 方案:Redis、MongoDB。
开源框架:
- UidGenerator(百度):基于
Snowflake(雪花算法); - Leaf(美团)
- Tinyid(滴滴)
- ZooKeeper 这类中间件也可生成唯一 ID
Hutool 唯一ID工具-IdUtil
在分布式环境中,唯一ID生成应用十分广泛,生成方法也多种多样,Hutool针对一些常用生成策略做了简单封装。
唯一ID生成器的工具类,涵盖了:
- UUID
- ObjectId(MongoDB)
- Snowflake(Twitter)
UUID
UUID(universally unique identifier,通用唯一识别码),JDK通过java.util.UUID提供了 Leach-Salz 变体的封装。
在Hutool中,生成一个UUID字符串方法如下:
- 如果全球唯一性是绝对关键的,推荐使用遵循RFC 4122标准的:(包含
-分隔符)randomUUID():生成符合RFC 4122标准的UUID。UUID包含时间戳、时钟序列、节点ID等信息,且格式固定,全局唯一。fastUUID():快速生成标准格式UUID的方法,格式同上。
- 如果对唯一性要求不是那么严格,生成简化版UUID(基于时间戳和随机数,不包含
-的分隔符):simpleUUID():适用于需要较短且连续的字符串标识场景。fastSimpleUUID():快速生成简化版UUID。更适合作为数据库主键或者简单标识使用。
生成不带-的字符串:带 simple 的方法
1 | |
说明Hutool重写
java.util.UUID的逻辑,对应类为cn.hutool.core.lang.UUID,使生成不带-的UUID字符串不再需要做字符替换,性能提升一倍左右。
ObjectId
ObjectId是MongoDB数据库的一种唯一ID生成策略,是UUID version1的变种。
Hutool针对此封装了cn.hutool.core.lang.ObjectId,快捷创建方法为:
1 | |
Snowflake 雪花算法
分布式系统中,有一些需要使用全局唯一ID的场景,有时候希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。Twitter的Snowflake 算法就是这种生成器。
Snowflake 算法:生成简化的全局唯一ID。
- 是 Twitter 开源的分布式自增 ID 算法。
- 特点是:按时间有序、生成的结果小、生成效率高。
使用方法如下:
1 | |
冷热分离
数据冷热分离:指根据数据的访问频率和业务重要性,将数据分为冷数据和热数据。冷数据一般存储在低成本、低性能的介质中,热数据存储在高性能存储介质中。
- 热数据:指经常被访问和修改且需要快速访问的数据。缓存热点数据,存储在内存中,速度相当快。
- 冷数据:指不经常访问,对当前项目价值较低,但需要长期保存的数据。
冷热分离的思想
冷热分离的思想:对数据进行分类,然后分开存储。
可以应用到很多领域和场景中,例如:
- 邮件系统中,可以将近期的比较重要的邮件放在收件箱,将比较久远的不太重要的邮件存入归档。
优缺点
- 优点:
- 热数据的查询性能得到优化(用户的绝大部分操作体验会更好);
- 节约成本:根据冷热数据的不同存储需求,选择对应的数据库类型和硬件配置,比如将热数据放在 SSD 上,将冷数据放在 HDD 上。
- 缺点:
- 系统复杂性和风险增加(需要分离冷热数据,数据错误的风险增加);
- 统计效率低。
冷数据如何存储?
冷数据的存储要求主要是容量大、成本低、可靠性高,访问速度可以适当牺牲。
冷数据存储方案:
- 中小厂:直接使用 MySQL/PostgreSQL 即可(不改变数据库选型和项目当前使用的数据库保持一致),比如新增一张表来存储某个业务的冷数据、或者使用单独的冷库来存放冷数据(涉及跨库查询,增加了系统复杂性和维护难度)。
- 大厂:Hbase(常用)、RocksDB、Doris、Cassandra
如果公司成本预算足的话,也可以直接上 TiDB 这种分布式关系型数据库,直接一步到位。
- TiDB 6.0 正式支持数据冷热存储分离,可以降低 SSD 使用成本。
- 使用 TiDB 6.0 的数据放置功能,可以在同一个集群实现海量数据的冷热存储,将新的热数据存入 SSD,历史冷数据存入 HDD。
数据库连接池
在项目中,数据库连接池基本是必不可少的组件。在目前数据库连接池的选型中,主要是
- Druid:为监控而生的数据库连接池。Alibaba 开源的高性能数据库连接池。加入了强大的监控功能,可实时观察数据库连接池和 SQL 的运行情况,帮用户及时排查出系统中存在的问题。
- HikariCP:号称性能最好的数据库连接池。Spring Boot 默认数据源。
C3P0DBCP
至于怎么选择,两者都非常优秀,不用过多纠结。
- 阿里大规模采用 Druid 。
- Spring Boot 2.X 版本,默认采用 HikariCP 。
当然,如下有一些资料,胖友可以阅读参考:
HikariCP 和 Druid 的入门,会配置单数据源和多数据源情况下的连接池。
整合 HikariCP 连接池
依赖
配置文件
添加 HikariCP 配置:
- 在
spring.datasource配置项下,可以添加数据源的通用配置。定义了orders和users两个数据源的配置。- 在
.hikari配置项下,可以添加 HikariCP 连接池的自定义配置。然后DataSourceConfiguration.Hikari会自动化配置 HikariCP 连接池。
- 在
1 | |
数据源配置类
创建 DataSourceConfig 配置类。
- 这块代码,是参考 Spring Boot
DataSourceConfiguration.Hikari配置类来实现的。
1 | |
整合 Druid 连接池
依赖
1 | |
数据源配置
在 application.yml 文件中添加数据源配置,会与 Druid 数据源中的属性进行绑定;
- 将 Druid 的自定义配置,和
url、driver-class-name等数据源的通用配置放在同一级,这样后续只需要使用@ConfigurationProperties(prefix = "spring.datasource.orders")的方式,就能完成 DruidDataSource 的配置属性设置。 - 在
spring.datasource.druid配置项下,还配置了filter.stat和stat-view-servlet配置项,用于 Druid 监控功能。
1 | |
数据源配置类
数据库连接池、数据源自动配置;DataSourceAutoConfiguration 类;
自定义方式需创建数据源配置类:配置类创建 Druid 数据源对象时,应避免将数据源信息(如 URL、username、password 等)硬编码到代码中,可通过 @ConfigurationProperties("spring.datasource") 注解,将数据源属性与配置文件中以 spring.datasource 开头的配置绑定。
创建 DataSourceConfig 配置类。
- 因为在 「5.2 应用配置」 中,将 Druid 自定义的配置项,和数据源的通用配置放在了同一级,所以只需使用
@ConfigurationProperties(prefix = "spring.datasource.orders")这样的方式即可。
1 | |
监控功能
- 内置提供的名为
StatViewServlet的Servlet,可开启 Druid 内置监控页面功能, 展示 Druid 的统计信息;需将该Servlet配置在 Web 应用中的 WEB-INF/web.xml 中; - 内置提供的 StatFilter,可开启 Druid 的 SQL 监控功能;
- 内置提供了 WallFilter,可开启防火墙功能,防御 SQL 注入攻击。
- 通过
spring.datasource.filter.stat配置了 StatFilter ,统计监控信息。 - 通过
spring.datasource.filter.stat-view-servlet配置了 StatViewServlet ,提供监控信息的展示的 html 页面和 JSON API 。
所以在启动项目后,访问 http://127.0.0.1:8080/druid 地址,可以看到监控 html 页面。
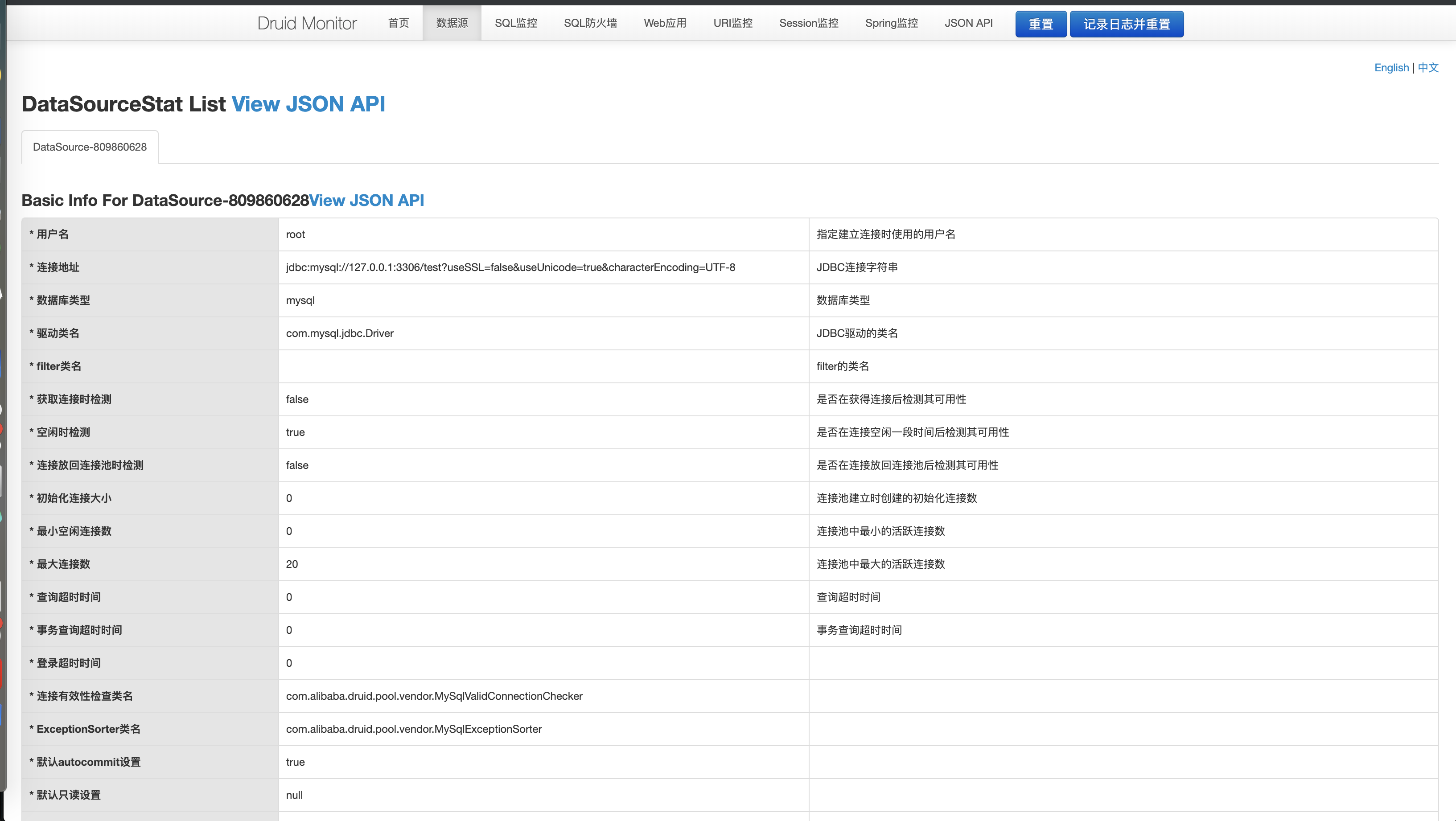
- 在界面的顶部,提供了数据源、SQL 监控、SQL 防火墙等等功能。
- 每个界面上,可以通过 View JSON API 获得数据的来源。同时,可以在 JSON API(
http://127.0.0.1:8080/druid/api.html) 菜单对应的界面中,看到 StatViewServlet 内置的监控信息的 JSON API 列表。 - 因为监控信息是存储在 JVM 内存中,在 JVM 进程重启时,信息将会丢失。如果我们希望持久化到 MySQL、Elasticsearch、HBase 等存储器中,可以通过 StatViewServlet 提供的 JSON API 接口,采集监控信息。另外,有个 druid-aggregated-monitor 开源项目,提供了 集中监控分布式服务中的 Druid 连接池的方案和思路。
- 如果 StatViewServlet 提供的 JSON API 接口,无法满足诉求,可以通过自定义 API 接口,使用 DruidStatManagerFacade 获得监控信息。使用示例 DruidStatController 代码。
测试类
Spring Boot 提供的默认测试类;
1 | |
数据权限
data-permisssion
多数据源
在项目中,可能会碰到需要多数据源的场景。
-
多数据源(分库?):一个复杂的单体项目,因为没有拆分成不同的服务,需要连接多个业务的数据源。
-
读写分离:数据库主节点压力比较大,需要增加从节点提供读操作,以减少压力。
- 本质上,读写分离,仅仅是多数据源的一个场景,从节点是只提供读操作的数据源。所以只要实现了多数据源的功能,也就能够提供读写分离。
实现方式
目前,实现多数据源有三种方案:
基于 AbstractRoutingDataSource
基于 Spring AbstractRoutingDataSource 做拓展。
- 简单来说,通过继承 AbstractRoutingDataSource 抽象类,实现一个管理项目中多个 DataSource 的动态 DynamicRoutingDataSource 实现类。
- 这样,Spring 在获取数据源时,可以通过 DynamicRoutingDataSource 返回实际的 DataSource 。
- 然后,可以自定义一个
@DS注解,可以添加在 Service 方法、Dao 方法上,表示其实际对应的 DataSource 。
如此,整个过程就变成,执行数据操作时,通过配置的 @DS 注解,使用 DynamicRoutingDataSource 获得对应的实际的 DataSource 。之后,在通过该 DataSource 获得 Connection 连接,最后发起数据库操作。
-
缺点:在结合 Spring 事务的时候,会存在无法切换数据源的问题。
-
比较好的开源项目是 baomidou 提供的
dynamic-datasource-spring-boot-starter。
如, 「3. baomidou 多数据源」 和 「4. baomidou 读写分离」
不同操作类,固定数据源
整个配置过程会相对繁琐
以 MyBatis 举例子,假设有 orders 和 users 两个数据源。
- 那么可以创建两个 SqlSessionTemplate
ordersSqlSessionTemplate和usersSqlSessionTemplate,分别使用这两个数据源。 - 然后,配置不同的 Mapper 使用不同的 SqlSessionTemplate 。
如此,整个过程就变成,执行数据操作时,通过 Mapper 可以对应到其 SqlSessionTemplate ,进而获得对应的实际的 DataSource 。之后获得 Connection 连接,最后发起数据库操作。
如, 「5. MyBatis 多数据源」、「6. Spring Data JPA 多数据源」、「7. JdbcTemplate 多数据源」 。
缺点:在结合 Spring 事务的时候,也会存在无法切换数据源的问题。
分库分表中间件
对于分库分表的中间件,会解析我们编写的 SQL ,路由操作到对应的数据源。那么,它们天然就支持多数据源。如此,仅需配置好每个表对应的数据源,中间件就可以透明的实现多数据源、或者读写分离。
目前,Java 最好用的分库分表中间件,就是 Apache ShardingSphere ,没有之一。
无法切换数据源的问题
这种方式在结合 Spring 事务的时候,不会存在无法切换数据源的问题。
-
在上述的方案一和方案二中,在 Spring 事务中,会获得对应的 DataSource ,再获得 Connection 进行数据库操作。而获得的 Connection 以及其上的事务,会通过 ThreadLocal 的方式和当前线程进行绑定。这样,就导致无法切换数据源。
-
虽然分库分表中间件也需要 Connection 进行这些事情,但是不同的是 Connection 返回的实际是动态的 DynamicRoutingConnection ,它管理了整个请求(逻辑)过程中,使用的所有的 Connection ,而最终执行 SQL 时,它会解析 SQL ,获得表对应的真正的 Connection 执行 SQL 操作。
-
难道方案一和方案二也可以这么做,前提是,他们要实现解析 SQL 的能力。
分库分表中间件(从一定程度上来说)就是多数据源的完美方案。
- 但是,它需要解决多个 Connection 可能产生的多个事务的一致性问题,即分布式事务。不过相信,Sharding-JDBC 最终会解决分布式事务的难题,提供透明的多数据源的功能。
应用场景
实际场景下怎么选择呢?
- 方案二:首先,基本排除了方案二【不同操作类,固定数据源】。配置繁琐,使用不变。
- 这种方案,更加适合不同类型的数据源,例如说一个项目中,既有 MySQL 数据源,又有 MongoDB、Elasticsarch 等其它数据源。
- 方案一:然后,对于大多数场景下,方案一【基于 SpringAbstractRoutingDataSource 做拓展】,基本能够满足。
- 这种方案,目前是比较主流的方案,大多数项目都采用。
- 在实现上,可以比较容易的自己封装一套,当然也可以考虑使用
dynamic-datasource-spring-boot-starter开源项目。
- 当然,方案一和方案二,会存在和 Spring 事务结合的时候,在事务中无法切换数据源。
- 这是因为 Spring 事务会将 Connection 和当前线程变量绑定定,后续会通过线程变量重用该 Connection ,导致无法切换数据源。
- 所以,方案一和方案二,可以理解成 DataSource 级别上实现的数据源方案。
- 方案三:最后,【分库分表中间件】是完美解决方案,基本满足了所有的场景。
- 个人强烈推荐使用 Apache ShardingSphere 的 Sharding-JDBC 组件,无论胖友是有多数据源,还是分库分表,还是读写分离,都能完美的匹配。
- 并且,Apache ShardingSphere 已经提供多种分布式事务方案,也能解决在文章的开头,提到的分布式事务的问题。这种类型的方案,目前很多大厂都是这样去玩的。
- 京东:采用 client 模式的读写分离和分库分表。
- 美团:采用 client 模式的读写分离和分库分表。
- 陌陌:采用 client 模式的读写分离和分库分表。
方案一
baomidou 多数据源
使用 test_orders 和 test_users 两个数据源作为两个数据源,然后实现在其上的 SQL 操作。并且,会结合在 Spring 事务的不同场景下,会发生的结果以及原因。
- order 表、user 表分别位于不同的数据库。
- 不分主从,没有备份。
依赖
Application
创建 Application.java 类
- 添加
@MapperScan注解,指定 Mapper 接口所在的包路径。 - 添加
@EnableAspectJAutoProxy注解,重点是配置exposeProxy = true,因为希望 Spring AOP 能将当前代理对象设置到 AopContext 中。
1 |
|
配置文件
在 resources 目录下,创建 application.yaml 配置文件。
主要是 spring.datasource.dynamic 配置项
1 | |
MyBatis 配置文件
在 resources 目录下,创建 mybatis-config.xml 配置文件。
- 因为在数据库中表的字段,是使用下划线风格,而数据库实体的字段使用驼峰风格,所以通过
mapUnderscoreToCamelCase = true来自动转换。
1 | |
实体类
Mapper
@DS 注解,是 dynamic-datasource-spring-boot-starter 提供,可添加在 Service 或 Mapper 的类/接口上,或者方法上。在其 value 属性种,填写数据源的名字。
- OrderMapper 接口上,添加了
@DS(DBConstants.DATASOURCE_ORDERS)注解,访问 orders 数据源。 - UserMapper 接口上,添加了
@DS(DBConstants.DATASOURCE_USERS)注解,访问 users 数据源。
1 | |
baomidou 读写分离
示例代码对应仓库:lab-17-dynamic-datasource-baomidou-02 。
在绝大多数情况下,使用多数据源的目的,是为了实现读写分离。
- 分主从库。
- user 库?
其它与多数据源一致。
应用配置文件
在 resources 目录下,创建 application.yaml 配置文件。
- 相比 「3.3 应用配置」 来说,配置了订单库的多个数据源:
- master :订单库的主库。
- slave_1 和 slave_2 :订单库的两个从库。
- 在 dynamic-datasource-spring-boot-starter 中,多个相同角色的数据源可以形成一个数据源组。
- 判断标准是,数据源名以下划线 _ 分隔后的首部即为组名。例如说,slave_1 和 slave_2 形成了 slave 组。
- 可以使用
@DS("slave_1")或@DS("slave_2")注解,明确访问数据源组的指定数据源。 - 也可以使用
@DS("slave")注解,此时会负载均衡,选择分组中的某个数据源进行访问。目前,负载均衡默认采用轮询的方式。
因为本地并未搭建 MySQL 一主多从的环境,所以是通过创建了
test_orders_01、test_orders_02库,手动模拟作为test_orders的从库。
- user 库?
1 | |
OrderDO
只使用 「3.5 实体类」 的 OrderDO.java 类。
OrderMapper
创建 OrderMapper.java 接口。
DBConstants.java类,枚举了DATASOURCE_MASTER和DATASOURCE_SLAVE两个数据源。
1 | |
在 resources/mapper 路径下,创建 OrderMapper.xml 配置文件。
方案二
MyBatis 多数据源
配置文件
在 resources 目录下,创建 application.yaml 配置文件。
- 注释掉
mybatis配置项,因为不使用mybatis-spring-boot-starter自动化配置 MyBatis ,而是自己写配置类,自定义配置 MyBatis 。
1 | |
配置类
在 cn.iocoder.springboot.lab17.dynamicdatasource.config 包路径下,我们会分别创建:
- MyBatisOrdersConfig 配置类,配置使用
orders数据源的 MyBatis 配置。 - MyBatisUsersConfig 配置类,配置使用
users数据源的 MyBatis 配置。
两个 MyBatis 配置类代码是一致的,只是部分配置项的值不同。所以我们仅仅来看下 MyBatisOrdersConfig 配置类,而 MyBatisUsersConfig 配置类胖友自己看看即可。
1 | |
读写分离
按照这个思路,如果想要实现 MyBatis 读写分离。还是类似的思路。只是将从库作为一个“特殊”的数据源,需要做的是:
- 应用配置文件增加从库的数据源。
- 增加一套从库的 MyBatis 配置类。
- 增加一套从库相关的 MyBatis Mapper 接口、Mapper XML 文件。
相比方案一【基于 Spring AbstractRoutingDataSource 做拓展】来说,更加麻烦。并且,万一有多从呢?
所以呢,实际项目在选型时,方案一会优于方案二,被更普遍的采用。
Spring Data JPA 多数据源
整个过程,和 「5. MyBatis 多数据源」 是类似的。
配置文件
在 resources 目录下,创建 application.yaml 配置文件。
1 | |
配置类
创建 HibernateConfig.java 配置类。
- 目的是获得 Hibernate Vendor 相关配置。
1 | |
分别创建:
- JpaOrdersConfig 配置类,配置使用
orders数据源的 Spring Data JPA 配置。 - JpaUsersConfig 配置类,配置使用
users数据源的 Spring Data JPA 配置。
JdbcTemplate 多数据源
整个过程,和 「5. MyBatis 多数据源」 是类似的
方案三
Sharding-JDBC 多数据源
Sharding-JDBC 是 Apache ShardingSphere 下,基于 JDBC 的分库分表组件。对于 Java 语言来说,推荐选择 Sharding-JDBC 优于 Sharding-Proxy ,主要原因是:
- 减少一层 Proxy 的开销,性能更优。
- 去中心化,无需多考虑一次 Proxy 的高可用。
Application
和 「3.2 Application」 是完全一致的。
创建 Application.java 类
1 |
|
配置文件
在 resources 目录下,创建 application.yaml 配置文件。
- 结合使用 Hikari 数据库连接池
spring.shardingsphere.datasource配置项下,配置了ds_orders和ds_users两个数据源。spring.shardingsphere.sharding配置项下,配置了分片规则,
1 | |
Sharding-JDBC 读写分离
Sharding-JDBC 已经提供了读写分离的支持,可以看看如下两个文档:
未提及的部分与 Sharding-JDBC 多数据源一致
配置文件
在 resources 目录下,创建 application.yaml 配置文件。
spring.shardingspheredatasource配置项下,配置了 一个主数据源ds-master、两个从数据源ds-slave-1、ds-slave-2。masterslave配置项下:配置了读写分离。对于从库来说,Sharding-JDBC 提供了多种负载均衡策略,默认为轮询。
mybatis配置项,设置mybatis-spring-boot-starterMyBatis 的配置内容。
因为本地并未搭建 MySQL 一主多从的环境,所以是通过创建了
test_orders_01、test_orders_02库,手动模拟作为test_orders的从库。
1 | |